
爆发性的 AI 应用:风险与机遇并存
在空间和环境科学领域,AI 工具的应用越来越广泛——诸如天气预报和气候模拟,能源及水资源管理等等。可以说,我们正在经历前所未有的 AI 应用爆发,面对其中的机遇与风险,更加需要审慎思考。
美国地球物理联盟 (AGU) 的跟踪报告进一步揭示了 AI 工具的广泛应用,从 2012-2022年,摘要中提到 AI 的论文数量呈现指数级增长,这凸显了其在天气预报、气候模拟、资源管理等方面的巨大影响。

AI 相关论文发表趋势
然而,AI 释放强大能量的同时也带来了潜在的风险,其中,训练不足的模型或不当设计的数据集,可能导致不可靠的结果甚至潜在危害。例如,将龙卷风报告作为输入数据集,训练数据可能会偏向人口稠密的地区,因为在那里会观察和报告更多的天气事件。作为结果,该模型可能会高估城市地区的龙卷风,低估农村地区的龙卷风,从而造成危害。
这一现象也引发了重要思考——人们在什么时候、什么程度上能够信任 AI,规避可能产生的风险?
在 NASA 的支持下,AGU 召集专家制定了一套「在空间和环境科学中应用人工智能」的指导方针,着重关注了 AI 应用中可能存在的伦理和道德问题,不仅仅局限于空间与环境科学这一特定领域,更为全方位的 AI 应用提供了引导。相关内容已发表于「Nature」。

论文发表于Nature
论文链接:
https://www.nature.com/articles/d41586-023-03316-8
帮助建立信任的六大指导方针
目前,很多人对于 AI/ML 的可信问题仍持观望态度。为帮助研究人员/科研机构建立对 AI 的信任,AGU 建立了六大指导方针:为保留原意,笔者将译文和原文一并附上
对研究人员的指导
1. Transparency, Documentation and Reporting
在 AI/ML 研究中,透明度和全面的文件记录至关重要。不仅要提供数据和代码,还要记录参与者及问题解决方式,包括处理不确定性和偏见。透明度应贯穿研究的始终,从概念开发到应用过程中都需考虑。
2. Intentionality, Interpretability, Explainability, Reproducibility and Replicability
在使用 AI/ML 进行研究时,必须着重考虑意向性、可解释性、可重复性和可复制性。优先选择开放式科学方法,提高模型的可解释性和可重复性,鼓励开发解释 AI 模型的方法。
3. Risk, Bias and Effects
了解和管理数据集及算法的潜在风险和偏见对研究至关重要。通过更好地理解风险和偏见的来源,以及识别这些问题的方法,能更有效地管理和应对不利结果,最大限度地扩大公共利益和效果。
4. Participatory Methods
在 AI/ML 研究中,采用包容性设计和实施方法是非常重要的。确保不同社区、专业领域和背景的人都有发言权,特别是对于可能受到研究影响的社区。共同生产知识、参与项目和协作对于确保研究的包容性至关重要。
对学术组织(包括研究机构、出版社、协会和投资人)的指导
5. Outreach, Training and Leading Practices
学术组织需要为各个行业提供支持,确保提供有关 AI/ML 伦理使用的培训,包括研究人员、从业者、资助者和更广泛的 AI/ML 社区。科学协会、机构和其他组织应提供资源和专业知识,支持 AI/ML 道德培训,并教育社会决策者了解 AI/ML 在研究中的价值和局限性,以便做出负责任的决策,从而减少其负面影响。
6. Considerations for Organizations, Institutions, Publishers, Societies and Funders
学术组织有责任牵头建立和管理 AI/ML 道德问题的相关政策,包括行为准则、原则、报告方法、决策过程和培训,应阐明价值观,设计治理结构,包括文化建设,以确保道德 AI/ML 实践得以贯彻。此外,跨组织和机构执行这些责任是必要的,以确保道德实践在整个领域中得到落实。
关于 AI 应用的更详细建议
1. 留意偏差(Watch out for gaps and biases)
当涉及人工智能模型和数据时,务必警惕其中的空白和偏见。数据质量、覆盖范围和种族偏见等因素都能影响模型结果的准确性和可靠性,这可能带来意想不到的风险。
例如,某些地区的环境数据覆盖范围或真实性远优于其他地区。云层遮挡频繁的地区(如热带雨林)或传感器覆盖较少的地区(如极地),将提供较少的代表性数据。数据集的丰富性和质量常偏向富裕地区,忽视弱势群体,包括长期受歧视的社区。而这些数据通常用于为公众、企业和政策制定者提供建议和行动方案,例如在健康数据中,基于白人数据训练的皮肤病学算法在诊断黑人的皮肤损伤和皮疹方面准确性较低。机构应着重培训研究人员,审视数据和模型的准确性,并设立专业委员会监督人工智能模型的使用。
2.开发解释人工智能模型工作原理的方法(Develop ways to explain how AI models work )
研究人员在使用经典模型进行研究并发表论文时,读者通常希望他们提供底层代码和相关规范的访问权限。然而,目前尚未明确要求研究者提供此类信息,导致他们使用的 AI 工具缺乏透明度和可解释性。这意味着,即使使用相同的算法处理相同的实验数据,不同的实验方式也可能无法精确地复制结果。所以,在已公开发表的研究中,研究人员应清晰记录如何构建、部署人工智能模型,以供他人评估结果。
研究人员建议进行跨模型的比较,并将数据源分成比较组以检查。行业迫切需要进一步的标准和指导来解释和评估人工智能模型的工作方式,以便在产出结果的同时进行与统计信心水平相当的评估。
目前,研究人员和开发人员正在研究一种称为可解释 AI (XAI) 的技术,旨在通过量化或可视化输出,使用户更好地理解人工智能模型的运作方式。比如,在短期天气预报中,人工智能工具能够分析每隔几分钟就获得的大量遥感观测数据,从而提高对严重天气灾害的预测能力。
清晰地解释产出结果的达成方式对于评估预测的有效性和实用性至关重要。比如,在预测火灾或洪水的可能性和程度时,这种解释能帮助人类判断是否向公众发出警报,或者使用其他人工智能模型的输出。在地球科学领域,XAI 试图量化或可视化输入数据的特征,以更好地理解模型输出的情况。研究人员需要检查这些解释,并确保其合理性。

人工智能工具正被用于评估环境观测
3. 建立伙伴关系,提高透明度(Forge partnerships and foster transparency)
研究人员需要在每个阶段都注重透明度:分享数据和代码、考虑进一步的测试以确保可复制性和可重复性、应对方法中的风险和偏差、以及报告不确定性。这些步骤需要更详细地描述方法。为确保全面性,研究团队的人员构成中应包含使用各类数据的专家,同时邀请参与提供数据或可能受研究结果影响的社区成员。例如,有个基于人工智能的项目结合了加拿大塔鲁人的传统知识和非本土方法收集的数据,以确定最适合进行水产养殖的地区(详见 go.nature.com/46yqmdr)。

水产养殖项目图片
4. 持续支持数据整理和监管(Sustain support for data curation and stewardship)
跨学科研究领域对于数据、代码和软件报告的要求需要符合 FAIR 原则:可找到、可访问、可互操作和可重用。为了建立对人工智能和机器学习的信任,需要公认、质量可靠的数据集,并且公开错误和解决方案。
当前面临的挑战是数据的存储,如通用存储库的广泛使用可能导致元数据问题,影响数据来源跟踪和自动访问。一些先进的学科研究数据存储库提供质量检查和信息补充的服务,但这通常需要投入人力和时间成本。
此外,文章还提到了对存储库的资金支持、不同存储库类型的限制以及对特定领域存储库的需求不足等问题。学术组织、资助机构等应当对支持和维护适当的数据存储库提供持续金融投资。
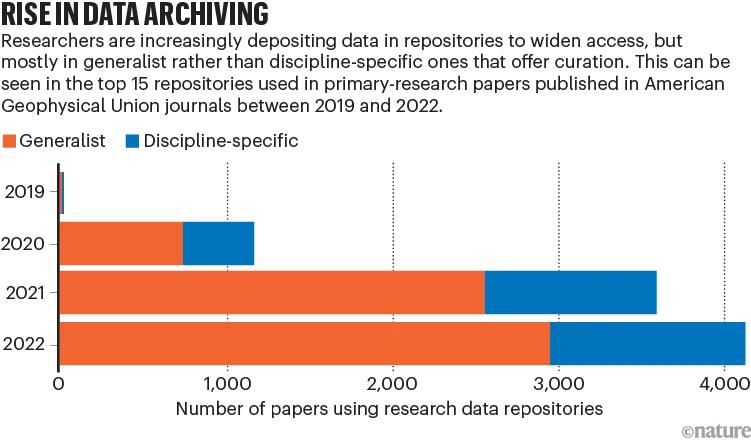
研究者越来越倾向于选择通用的数据存储库
5. 关注长期影响(Look at long-term impact)
在研究人工智能和机器学习在科学领域广泛应用的过程中,必须着眼于长期影响,确保这些技术能够减少社会差距、增强信任,积极包容不同意见和声音。
关于 AI 使用,听听中国怎么说
「怎么使用 AI,怎么用好 AI」,同样也是我国 AI 领域近年来的热议话题。
今年的两会代表眼中,人工智能是数字技术创新最活跃的领域之一,以生成式 AI(AIGC)、大规模预训练模型、知识驱动 AI 为代表的新技术释放着行业新机遇,需要抓住技术发展的「时间窗口」。
小米集团创始人、董事长兼 CEO 雷军提出鼓励扶持科创产业链,推进仿生机器人产业规划布局;加快制定汽车全生命周期的数据安全标准,指导产业发展;构建汽车数据共享机制及平台,促进汽车数据共享使用。
360 创始人周鸿祎则希望打造中国的「微软+OpenAI」组合,引领大模型技术攻关,打造开源众包的开放创新生态。
张伯礼院士建议设立生物医药制造重大专项,支持智能制药关键技术与装备研发,鼓励生物制药装备的发展。
由此可见,两会代表、委员均十分看好人工智能赛道。不止赋能科技,我们更期待在建立信任,谨慎使用的方针下,AI 能够更好的帮助企业和社会的发展。



 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的