
春节假期,人工智能领域进展神速。省流一点 ,您需要了解这些内容:
OpenAI 发布了他们的视频生成模型 Sora。它非常出色。
谷歌发布了 Gemini 1.5 Pro,性能接近 1.0 Ultra,并且文本长度几乎无限(最多可达 1 千万tokens)。
在ChatBot Arena平台中发现了一个名为 Mistral-Next 的模型,暗示其即将发布。初步测试表明,它至少是一个可靠的模型。

以下主要内容译自Interconnects文章《OpenAI’s Sora for video, Gemini 1.5's infinite context, and a secret Mistral model》,原文作者Nathan Lambert
01 Sora:OpenAI 的文生视频模型
我们早就知道它会出现,但还是被它的出色表现震惊了。你需要看一些人工智能生成的视频。OpenAI 发布了 Sora,山姆·奥特曼花了一整天时间在推特上分享其神奇世代的视频。当天晚些时候,OpenAI 发布了一篇技术性稍强的博文,证实了人们所关注的大部分传言。
简而言之,Sora 是视觉转换器(ViT)和扩散模型的组合。视觉转换器和 Sora 数据处理背后的核心理念似乎是将视频片段嵌入一个名为 "patch"的潜在空间,然后将其作为一个token。
引自 OpenAI 博客:
Sora 是一个扩散模型;在输入噪声patches(以及文本提示等条件信息)的情况下,经过训练,它可以预测原始的 "干净 "patches。重要的是,Sora 是一个扩散变换器。变换器在语言建模、计算机视觉和图像生成等多个领域都表现出卓越的扩展特性。
在这项工作中,我们发现扩散变换器作为视频模型也能有效扩展。
Lambert认为,博文中提到了很多有趣的东西,但都不是真正重要的东西,比如模型大小、架构或数据。数据几乎肯定是一大堆YouTube和一些程序化生成的视频(来自游戏引擎或其他自定义的东西,稍后详述)。需要知道的事情:
他们在多种分辨率(大多数多模态模型都固定在 256x256 等分辨率)上进行训练,包括 1920x1080p 横向或纵向分辨率。
"我们将重新字幕技术引入DALL-E 3图像生成器,应用于视频"。这包括两点:
让语言模型对提示进行调解对于获得良好的输出结果仍然非常重要。除非有必要,否则人们不会这么做。我认为这最终会通过更好的数据控制来解决。
更重要的是,这与他们的 "高度描述性字幕机模型"(将视频转换为文本)相关联,而这是为数据提供标签所必需的。这证实了基本的 GPT4 可以做到这一点,或者 OpenAI 还有许多其他最先进的模型隐藏在里面。
Sora 还能通过接收图像输入来完成动画、编辑和类似操作。
Sora 可以通过视频输入进行视频编辑。
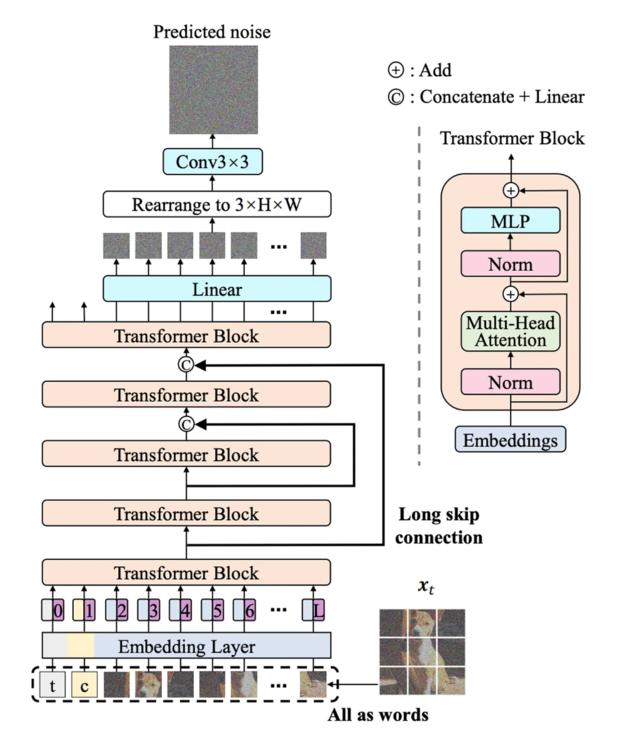
推特上的一个ML 的匿名账户挖出了一篇类似架构的论文,架构图如下。
Sora 最令人印象深刻的特点是它能够逼真地模拟物理世界(OpenAI 将其描述为 "新兴的模拟能力")。在此之前,还没有任何文生视频模型能与之相媲美。几周前,谷歌的 Lumiere 刚刚问世,给人留下了深刻印象,但与 Sora 相比,它显得非常逊色。

有很多传言说,神经辐射场(NeRFs)是一种流行的图像 3D 重构技术,它可能会根据视频的特征(就像物理世界一样)在引擎盖下使用,但我们没有明确的证据证明这一点。Lambert认为,这是程序生成的游戏引擎内容。仅仅使用游戏是不够的,你需要一种生成数据多样性的方法,就像所有合成数据一样。我们在 HuggingFace 为 RL 代理构建的数据就是一个很好的例子。数据的多样性可能会在生成过程中释放出另一个层次的性能——我们在大型模型中经常看到这种情况。
所有关于 Pika 和 Runway ML(其他流行的 ML 视频初创公司)死亡的评论都完全是夸大其词。如果进步的速度如此之快,那么我们还有很多转弯。如果最佳模型来得快去得也快,那么最重要的就是用户接触点。这一点在视频领域还没有建立起来,而且,MidJourney 还在依赖 Discord(不过,用户体验还很不错)!
02 Gemini1.5:谷歌的有效无上限文本长度
在 Sora 发布前几个小时,谷歌已经发布了 Gemini 的下一个版本,令所有人震惊。这可能会给人们使用 LLMs 的方式带来的直接变化,可以说比 Sora 视频更有影响力,但 Sora 的视觉演示质量令人着迷。
总结:
Gemini 1.5 Pro 的性能接近 Gemini 1.0 Ultra,但单位参数效率更高,并增加了 混合专家系统(MoE)作为基本架构。
Gemini 1.5 Pro 文本长度可扩展至 1 千万。作为参考,当 OpenAI 将 GPT4 增加到 128k 时,这就是件大事。一千万几乎没有任何意义——它又不是变形金刚。但它能接收的信息量远远超过普通 ChatGPT 用户的想象。
谷歌可能找到了某种新方法,将长上下文的架构理念与他们的 TPU 计算堆栈相结合,并取得了很好的效果。据 Gemini 长语境的负责人之一Pranav Shyam说,这个想法几个月前才刚刚萌芽。如果以小版本(v1.5)而不是 v2 发布,肯定会有更大的发展空间。
作为一个思想实验,围绕 Gemini 1.5 的交流告诉你,你可以在模型的上下文中包含整个生产代码库(参见 Google 提供的示例)。这对于那些还没有流行到会为下一个 GPT 版本而被搜刮成百上千次的库来说,确实能改变它们的命运。作为一款企业工具,它价值连城。他们将一千万个tokens可视化为多少内容,这可是一大笔财富。想想 3 小时的视频或 22 小时的音频在没有分割或损失的情况下被一个模型处理。
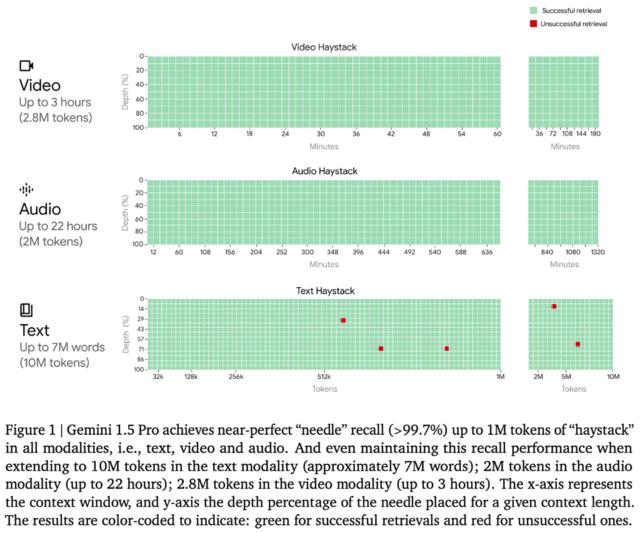
需要明确的是,付费的Gemini用户很快就能使用 100 万文本长度(类似于 ChatGPT plus 计划),而技术报告中也提到了 1000 万窗口。Lambert认为,目前保留它更多的是出于成本考虑。任何模型的计算量都很大。
这个关于上下文长度的数字让我伤透了脑筋。最长的上下文窗口更精确。
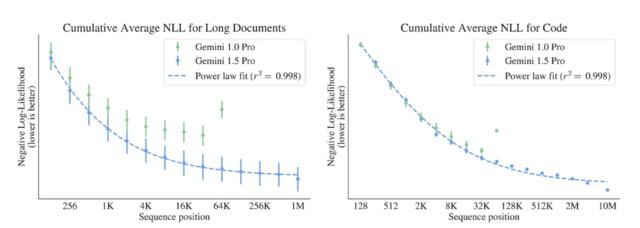
看到这一点,我们就会明白,这个模型并不是一个变形器。它有办法通过非注意力模型路由信息。很多人提到了 Mamba,但更有可能的是谷歌利用优化的 TPU 代码实现了自己的模型架构。Mamba 附带特殊的 Nvidia 内核和集成。
Lambert对此感到非常兴奋,因为在未来,我们与之交互的模型会将计算分配给专门从事不同任务的子模型。Lambert预计,如果我们看到 Gemini 1.5 Pro 架构图,它会更像一个系统,而不是普通的语言模型图。这就是研发阶段的样子。
著名的快速工程师Riley Goodside曾分享过这种类型的变化:
这里有很多含义。既然可以 100K-shot,为什么还要[监督微调]?如果有了语法和字典,它就能翻译Kalamang语,那么正确的词语又能教会它什么呢?
从根本上说,这意味着我们现在可以直接告诉模型如何在上下文中行动。微调不再需要能力。Lambert认为,这将会产生协同效应,而且当推理达到一定规模时,微调的成本会更低,但这还是令人兴奋的。
更多信息,请参阅谷歌Gemini 1.5 博客文章或技术报告。
最后,Perplexity 公司的首席执行官在接受采访时说,谷歌把他想聘用的人的待遇提高了四倍。这太疯狂了,我不知道这对谷歌来说是看涨还是看跌的信号。
03 Mistral-next:另一种有趣的发布方式
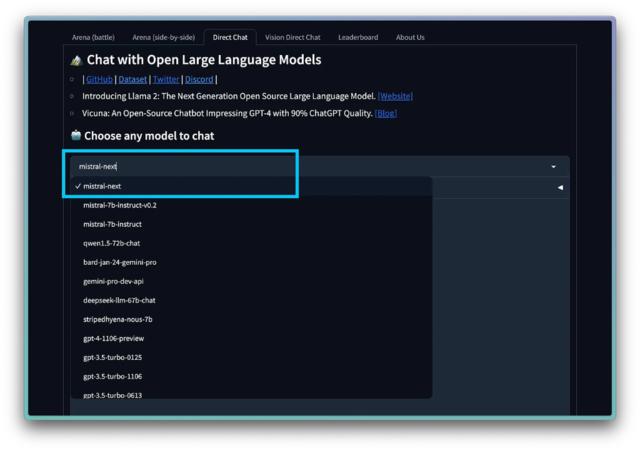
如果这还不够的话,在 LMSYS 竞技场上,还有另一款 Mistral 模型在偷偷地聊天。我听说过另一款模型即将推出的传言,但这款模型显然更加真实。
基本测试表明它是一款强大的机型。当然,Twitter 的暴民们现在会去举办更多的 vibes-evals 活动,但 Mistral 会很快告诉我们的。我猜这就是他们基于 API 的 GPT4 竞争对手。



 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的