
近日,Picsart AI Resarch等团队联合发布了StreamingT2V,可以生成长达1200帧、时长为2分钟的视频,一举超越Sora。同时,作为开源世界的强大组件,StreamingT2V可以无缝兼容SVD和animatediff等模型。
120秒超长AI视频模型来了!不但比Sora长,而且免费开源!
近日,Picsart AI Resarch等团队联合发布了StreamingT2V,可以生成长达1200帧、时长为2分钟的视频,同时质量也很不错。

论文地址:https://arxiv.org/pdf/2403.14773.pdf
并且,作者表示,两分钟并不是模型的极限,就像之前Runway的视频可以延长一样,StreamingT2V理论上可以做到无限长。

在Sora之前,Pika、Runway、Stable Video Diffusion(SVD)等视频生成模型,一般只能生成几秒钟的视频,最多延长到十几秒,

Sora一出,60秒的时长直接秒杀一众模型,Runway的CEO Cristóbal Valenzuela当天便发推表示:比赛开始了。

——这不,120秒的超长AI视频说来就来了。
这下虽说不能马上撼动Sora的统治地位,但至少在时长上扳回一城。
更重要的是,StreamingT2V作为开源世界的强大组件,可以兼容SVD和animatediff等项目,更好地促进开源生态的发展:

通过放出的例子来看,目前兼容的效果还稍显抽象,但技术进步只是时间的问题,卷起来才是最重要的~
总有一天我们都能用上「开源的Sora」,——你说是吧?OpenAI。
免费开玩
目前,StreamingT2V已在GitHub开源,同时还在huggingface上提供了免费试玩,等不了了,小编马上开测:
不过貌似服务器负载太高,上面的这个不知道是不是等待时间,反正小编没能成功。
目前试玩的界面可以输入文字和图片两种提示,后者需要在下面的高级选项中开启。
两个生成按钮中,Faster Preview指的是分辨率更低、时长更短的视频。
小编于是转战另一个测试平台(https://replicate.com/camenduru/streaming-t2v),终于获得一次测试机会,以下是文字提示:
A beautiful girl with short hair wearing a school uniform is walking on the spring campus
不过可能由于小编的要求比较复杂,导致生成的效果多少有点惊悚,诸位可以根据自己的经验自行尝试。
以下是huggingface上给出的一些成功案例:
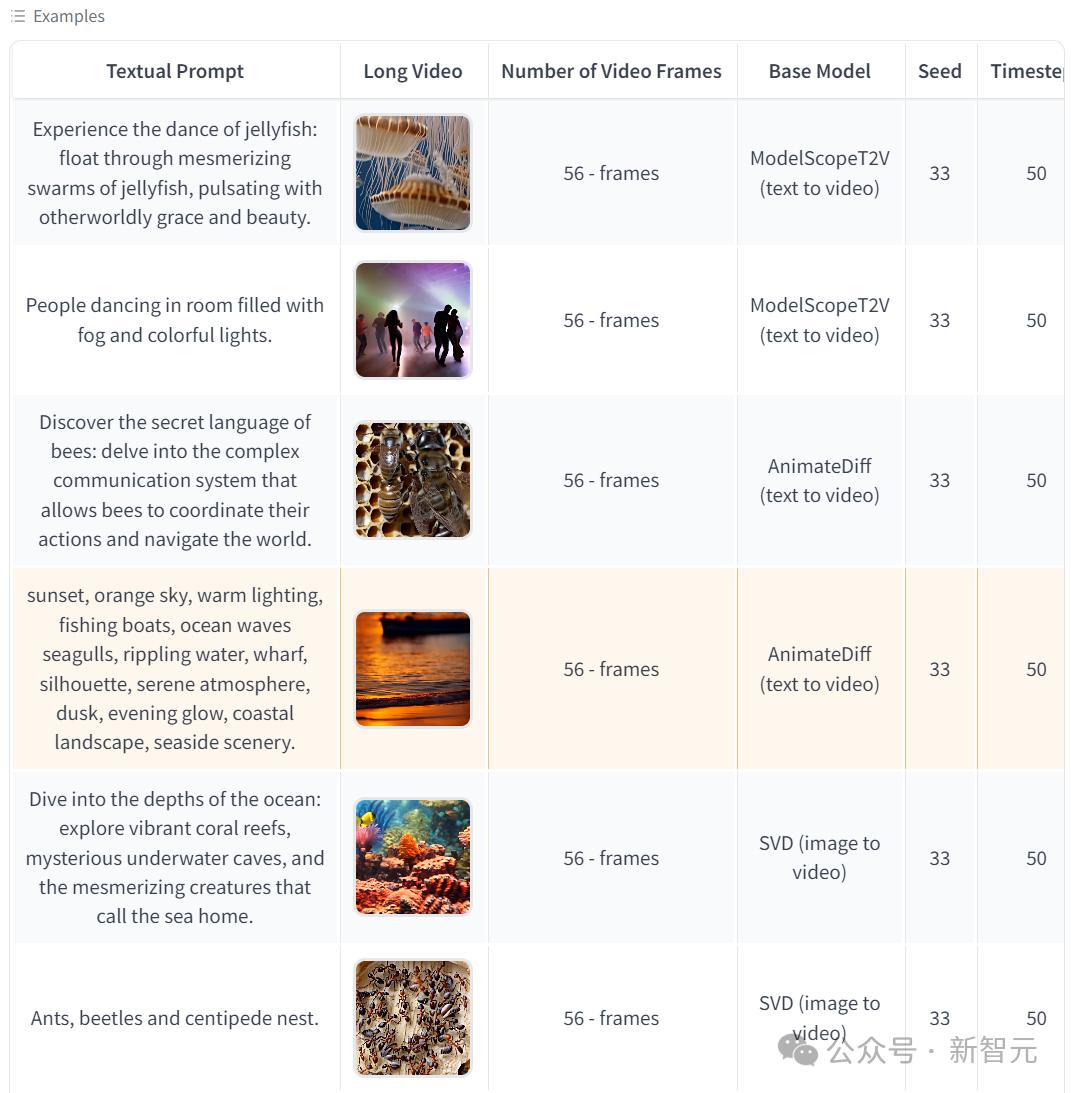
01 StreamingT2V

Sora的横空出世曾带来巨大的轰动,使得前一秒还闪闪发光的Pika、Runway、SVD等模型,直接变成了「前Sora时代」的作品。

不过就如同StreamingT2V的作者所言,pre-Sora days的模型也有自己的独特魅力。

模型架构
StreamingT2V是一种先进的自回归技术,可以创建具有丰富运动动态的长视频,而不会出现任何停滞。
它确保了整个视频的时间一致性,与描述性文本紧密对齐,并保持了高帧级图像质量。
现有的文本到视频扩散模型,主要集中在高质量的短视频生成(通常为16或24帧)上,直接扩展到长视频时,会出现质量下降、表现生硬或者停滞等问题。

而通过引入StreamingT2V,可以将视频扩展到80、240、600、1200帧,甚至更长,并具有平滑过渡,在一致性和运动性方面优于其他模型。
StreamingT2V的关键组件包括:
(i)称为条件注意力模块(CAM)的短期记忆块,它通过注意机制根据从前一个块中提取的特征来调节当前一代,从而实现一致的块过渡;
(ii)称为外观保留模块(APM)的长期记忆块,它从第一个视频块中提取高级场景和对象特征,以防止模型忘记初始场景;
(iii)一种随机混合方法,该方法能够对无限长的视频自动回归应用视频增强器,而不会出现块之间的不一致。
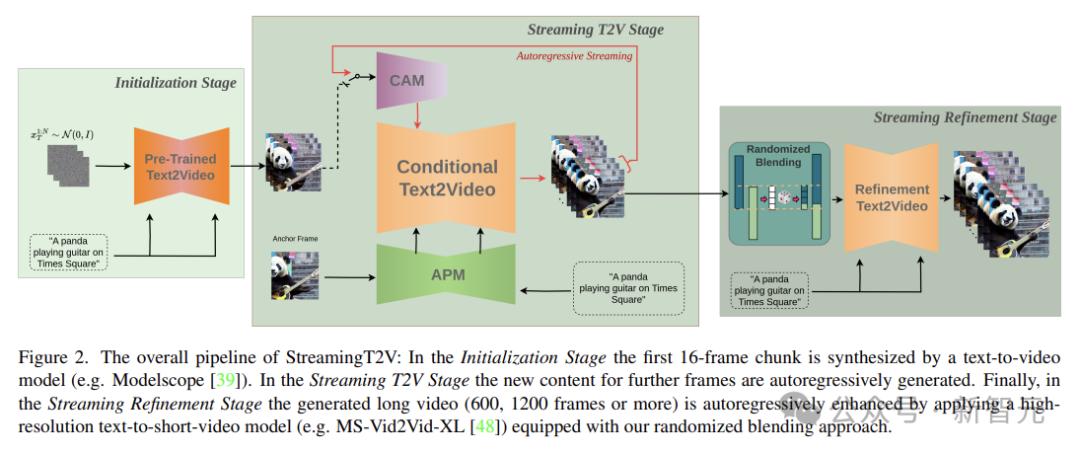
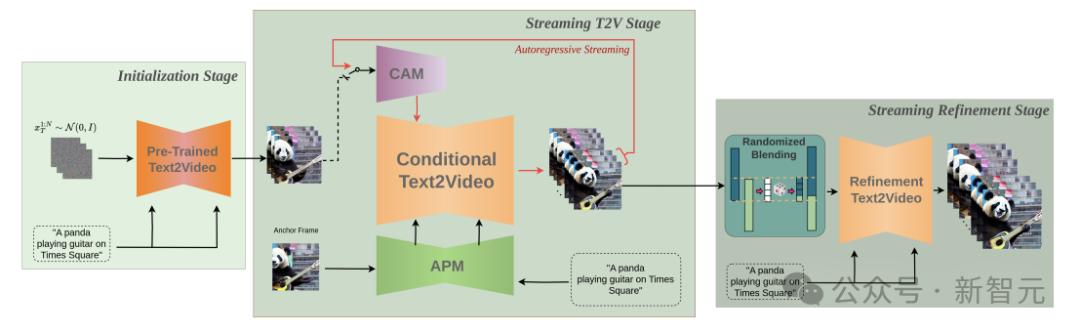
上面是StreamingT2V的整体流水线图。在初始化阶段,第一个16帧块由文本到视频模型合成。在流式处理 T2V 阶段中,将自动回归生成更多帧的新内容。
最后,在流优化阶段,通过应用高分辨率文本到短视频模型,并配备上面提到的随机混合方法,生成的长视频(600、1200帧或更多)会自动回归增强。

上图展示了StreamingT2V方法的整体结构:条件注意力模块(CAM)作为短期记忆,外观保留模块(APM)扩展为长期记忆。CAM使用帧编码器对前一个块上的视频扩散模型(VDM)进行条件处理。
CAM的注意力机制保证了块和视频之间的平滑过渡,同时具有高运动量。
APM从锚帧中提取高级图像特征,并将其注入到VDM的文本交叉注意力中,这样有助于在视频生成过程中保留对象/场景特征。
条件注意模块
研究人员首先预训练一个文本到(短)视频模型(Video-LDM),然后使用CAM(前一个区块的一些短期信息),对Video-LDM进行自回归调节。
CAM由一个特征提取器和一个特征注入器组成,整合到Video-LDM的UNet中,特征提取器使用逐帧图像编码器 E。
对于特征注入,作者使UNet中的每个远程跳跃连接,都关注CAM通过交叉注意力生成的相应特征。
CAM使用前一个块的最后一个Fconditional帧作为输入,交叉注意力能够将基本模型的F帧调节为CAM。
相比之下,稀疏编码器使用卷积进行特征注入,因此需要额外的F − Fzero值帧(和掩码)作为输入,以便将输出添加到基本模型的F帧中。这会导致SparseCtrl的输入不一致,导致生成的视频严重不一致。
外观保存模块
自回归视频生成器通常会忘记初始对象和场景特征,从而导致严重的外观变化。
为了解决这个问题,外观保留模块(APM)利用第一个块的固定锚帧中包含的信息来整合长期记忆。这有助于在视频块生成之间维护场景和对象特征。

为了使APM能够平衡锚帧的引导和文本指令的引导,作者建议:
(i)将锚帧的CLIP图像标记,与文本指令中的CLIP文本标记混合,方法是使用线性层将剪辑图像标记扩展到k = 8, 在标记维度上连接文本和图像编码,并使用投影块;
(ii) 为每个交叉注意力层引入了一个权重α∈R(初始化为0),以使用来自加权总和x的键和值,来执行交叉注意力。
自动回归视频增强
为了进一步提高文本到视频结果的质量和分辨率,这里利用高分辨率(1280x720)文本到(短)视频模型(Refiner Video-LDM)来自动回归增强生成视频的24帧块。
使用文本到视频模型作为24帧块的细化器/增强器,是通过向输入视频块添加大量噪声,并使用文本到视频扩散模型去噪来完成的。
然而,独立增强每个块的简单方法会导致不一致的过渡:

作者通过在连续块之间使用共享噪声,并利用随机混合方法来解决这个问题。
对比测试

上图是DynamiCrafter-XL和StreamingT2V的视觉比较,使用相同的提示。
X-T切片可视化显示,DynamiCrafter-XL存在严重的块不一致和重复运动。相比之下,StreamingT2V则可以无缝过渡、不断发展。
现有方法不仅容易出现时间不一致和视频停滞,而且随着时间的推移,它们会受到物体外观/特征变化,和视频质量下降的影响(例如下图中的SVD)。

原因是,由于仅对前一个块的最后一帧进行调节,它们忽略了自回归过程的长期依赖性。
在上图的视觉比较中(80帧长度、自回归生成视频),StreamingT2V生成长视频而不会出现运动停滞。
02 AI长视频能做什么
各家都在卷的视频生成,最直观的应用场景,可能是电影或者游戏。

用AI生成的电影片段(Pika,Midjourney,Magnific):

Runway甚至搞了个AI电影节:

不过另一个答案是什么呢?
世界模型

长视频创造的虚拟世界,是Agent和人形机器人最好的训练环境,当然前提是足够长,也足够真实(符合物理世界的逻辑)。
也许未来的某一天,那里也会是我们人类的生存空间。



 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的