
全场共提到 “ AI ” 121 次,平均一分半提一次。
今天凌晨 1 点( 太平洋时间 5 月 14 日上午 10 点 ),Google I/O 2024 大会的开幕主题演讲,在美国山景城正式举行。大会演讲在网络上公开直播的同时,也有部分媒体和观众来到了大会现场。
知危编辑部的前线同事,也到达了美国山景城参加了本次大会,全程观看了本次开幕主题演讲。

01
这位同事曾在 Google 前几年的鼎盛时期参加过一次 I/O 大会,用他的话来讲,那时候的 Google I/O 可以用四个字形容:万国来朝。
而如今,Google 的光环全都被 OpenAI 抢了去,本届 I/O 大会虽然依旧有很多人参加,但相较早年难免显得有些 “ 人丁不旺 ”。( 以前还卖票的,这次没卖 )
不过,在这场 I/O 大会上,Google 依然秀出了一些肌肉,对昨天的 GPT-4o 做出了强力回击。
谷歌 CEO 劈柴哥在演讲的一开始就坦然直言:目前正是整个行业正处于 AI 发展的早期,谷歌有信心和实力打这场持久战。
话里话外,一副 “ 你 OpenAI 别高兴得太早 ” 的味道。
纵观整场演讲,知危编辑部认为,如果去年谷歌的 I/O ,我们看到的是谷歌在 AI 领域的孤注一掷,那么今年,我们则发现谷歌这么一只巨无霸,正在 AI 的赛场上全方位一路狂奔,逐渐找回自己的状态。
本次主题演讲的内容,主打的是一个大而全,内容包含但不限于新基础模型、AI Agent、文生图模型、文生视频模型、TPU芯片、AI app、Android 与 AI 、新开源大模型等等等等。
知危编辑部也准备挑选其中几个比较亮眼产品,进行详细的介绍。
02
首先,知危编辑部觉得 OpenAI 昨日的春季发布会,有意狙击谷歌的的可能性非常之高。
因为谷歌本次重点推出的多模态 AI 助手 Project Astra ( 基于 Gemini ),功能与昨日横扫科技圈媒体头版的基于 GPT-4o 的 AI 助手极其类似。
同样拥有低延时的丝滑语音对话体验,同样也能用摄像头,让 AI 处理视觉信息。
在谷歌的演示视频中,Project Astra 能迅速认出音响的发声部位、彩笔,还能对屏幕上的代码进行一定程度上的解释。
它甚至还能根据箭头,提出在服务器和数据库之间添加缓存,能提高速度的建议,还能看懂画板上 “ 薛定谔的猫 ” 的梗图。
若不是昨日 GPT-4o 已经抢先亮相了一波,Project Astra 一定会被各路媒体打上 “ 炸裂 ”、“ 史诗 ”、“ 颠覆 ”、“ 改写历史 ” 等标签。
可惜,仅仅是晚了一天,现在大家对 Project Astra 的形容只有一个标签:“ 跟 GPT-4o 好像 ”。
不过,如果仔细观察演示视频,你会发现 Project Astra 的视频对话交互功能展现了一个 GPT-4o 并没有展示的功能:视频对话的过程是带有记忆的,即便是一个你可能从未向它提及的点。
这样形容起来有些抽象,看一下视频你就能明白了。
在视频中,Project Astra 注意到并记住了镜头经过的桌子上的眼镜,在与测试者进行多轮对话后还能指出眼镜在桌子上,并且还指出了 “ 旁边有一个苹果 ” 这样的细节,可以说是过目不忘,比人类强了不少。
而在文生视频领域,谷歌也对 Sora 发起追赶,在本次的主题演讲中,谷歌正式发布了视频生成大模型 Veo。
根据介绍,Veo 能以各种电影和视觉风格生成高质量的 1080p 分辨率视频,时长可以超过一分钟。Veo 能凭借对自然语言和视觉语义的深入理解,生成紧密代表用户创意愿景的视频。

此前我们曾介绍过,OpenAI 的 Sora 是基于 Diffusion Transformer,也就是 DIT 架构而成的。
但根据谷歌官方的介绍,Veo 采取的却是 GQN、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet 和 Lumiere 等 “ 老模型 ” 所组合而成的结合架构。
非常值得一提的是,谷歌在 Veo 的生成视频之下,标注了一行小字 “ All videos were generated by Veo and have not been modified. ”( 所有视频均由 Veo生成,未经修改)。
这个举动,应该是意在阴阳 OpenAI,OpenAI 的 Sora 正因被爆出演示视频经过了大量的人为后期修改而遭受广泛的质疑。

另外,对标 Midjourney 等文生图片大模型的 Imagen 3、对标 Suno 等音乐生成大模型的 Lyria、对标 GPT-4 Turbo 等轻量性能大模型的 Gemini 1.5 flash、对标 llama 3 等开源大模型的 Gemma 2,还有 Google 自家的新 TPU 等都在谷歌的本次开幕主题演讲上一一亮相。
03
看起来,谷歌似乎不愿放弃 AI 领域的任何一个赛道,想把自己打造成一个 AI 界的六边形全能战士。
而更可怕的是,在各个领域里,Google 相比友商虽然都不一定是最好的,但也并不落后多少。
同时,谷歌的上限和野心,肯定不限于此。本次的开幕式主题演讲中,谷歌还拿出来些不少其他 AI 厂家单打独斗绝对拿不出来的东西。知危编辑部认为,正是这些东西,有机会能让谷歌从 AI 领域的追赶者,跻身为领跑者。
因为谷歌,拥有其他 AI 巨头所没有的成熟系统与应用生态。
在演讲中,谷歌就展示了一波 Gemini 和 Google 相册的结合。
记不清自个儿车的车牌号,在 Google 相册里搜索 “ 查找车牌号 ”,拥有多模态能力的 Gemini 会从你的图片库中,找到你车的照片,并告诉你车牌号。
在谷歌 Gmail 邮箱里,你也能通过 AI 迅速提取邮箱里航班信息,同时 Google 地图以获取您酒店附近的餐厅和旅游景点,再给计划相应的日程。谷歌的老本行搜索,也在和 AI 相结合,你可以直接用文字进行搜索,也可以给图片画个圈儿,让搜索引擎自动搜索你圈出的部分。
甚至,你还可以上传视频对搜索引擎进行提问。比如在演示中,谷歌的员工就拍视频问问了 Gemini,相机上的那个杆卡住了咋办。

Gemini 马上就给出了基于搜索引擎的答案,看上去体验很好,可惜就是回答有些翻车,回答中的一个建议是 “ 把胶卷取出来看看 ”,而这样只会让整卷胶卷直接报废。。。
不过,我们只能说贵在真实吧,大模型乱讲话这事儿确实一直存在,自然展现比造假强一些。
04
总之,按照谷歌的说法,Gemini 大模型正在全面整合谷歌的那一大家产品中,包括在未来,他们将把 AI 直构建到 Android 操作系统的底层之中,准备改写用户和手机之间的交互方式。
他们举了一些例子,比如在用手机看书的时候,你可以直接给书里内容画圈儿,问 AI 圈儿里的提名怎么解;刷视频的时候, 也有可以直接问 AI ,视频里这运动员的动作是不是犯规;打电话的时候,AI 也能从你们的对话里,判断出对方是不是有可能是个骗子。
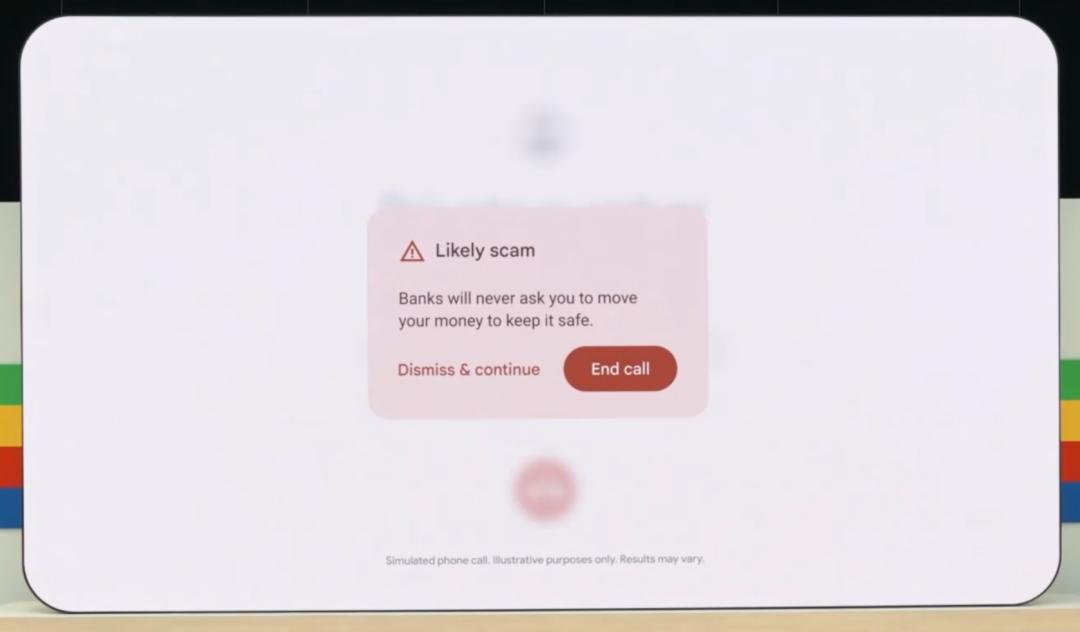
这样一来,在全面集成 Google 原生 AI 并且与原生 Google 应用打通的 Android 阵营面前,苹果如果不和 OpenAI 深度合作的话,我们只能说 Android 将在 AI 时代,对 iOS 进行一场降维碾压式打击。( 不过,6 月的 WWDC 上我们相信苹果肯定会搬出自己的 AI 方案来抵御这场进攻 )
总得来讲,这次谷歌的 I/O 大会啥产品都有,但要说出类拔萃,还谈不上。不过,在 AI 应用集成这一个最直面消费者的维度上看,谷歌还真是目前 AI 领域的集大成者之一。
这一波,去年还被称作是 AI 圈 “ 仲永” 的谷歌,算是渐入佳境了。



 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的