
AGI到底是科技公司画的大饼,还是可预测的未来?
几天前,Anthropic一名25岁的高管在博客上发文,表示自己已经准备好了3年后退休,让AI取代自己的工作。
最近,OpenAI前员工的一篇博客文章也有类似的观点。

他不仅认为AGI很可能实现,而且「奇点」预计就在2027年。
文章作者名为Leopold Aschenbrenner,于2023年入职OpenAI超级对齐团队,工作了1年6个月。
Aschenbrenner认为,到2027年,大模型将能够完成AI研究人员或工程师的工作。
他的论据也很简洁直观——你不需要相信科幻小说,只需要看到图上的这条直线。
画出过去4年GPT模型有效计算量的增长曲线,再延伸到4年后,就可以得出这个结论。
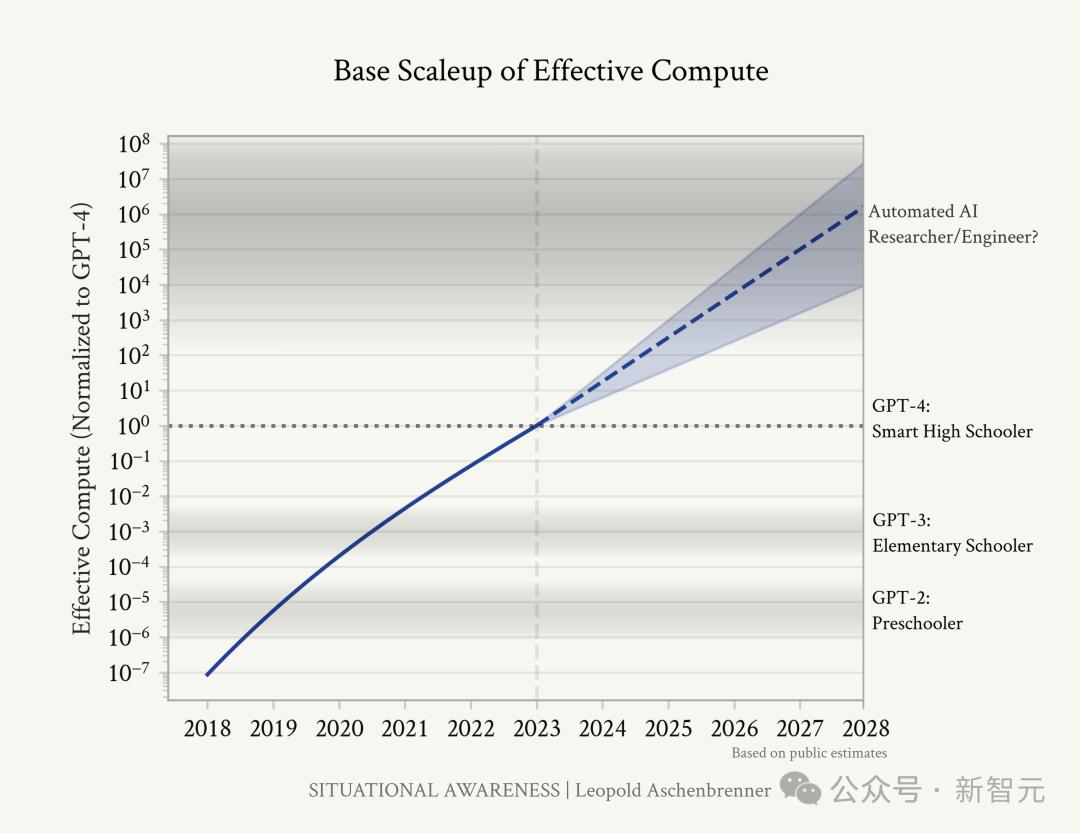
距离GPT-4发布已经过去了一年多的时间,包括Gary Marcus和Yann LeCun在内的很多人都不再对模型的Scaling Law深信不疑,甚至持否定态度。
虽然我们看起来正在碰壁,但Aschenbrenner提醒我们:往后退一步,看看AI已经走了多远。
直觉上,我们可以将模型能力类比为人类的智能水平,从而衡量AI能力的进步:从2019年学龄前儿童水平的GPT-2,到2023年聪明高中生水平的GPT-4,OpenAI只用了4年。
用4年从学龄前读到高中,是人类智力发展速度的3倍不止。
GPT-2只能写出一个半连贯的段落,几乎不能顺利地从1数到5。在文章总结任务中,生成的结果只比随机选3个句子稍微好一点。

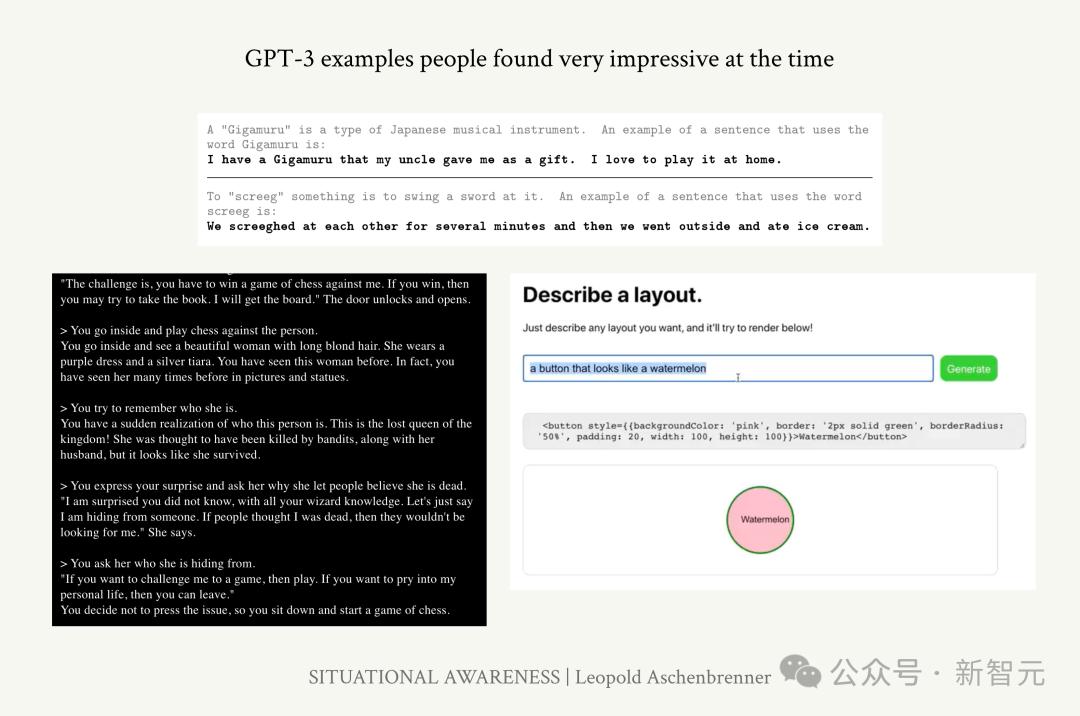
GPT-3能生成更长、逻辑更一致的段落,具备了少样本学习能力,还可以完成一些基本的算术或代码任务。
GPT-4不仅可以思考和推理数学问题,还能编写复杂的代码并迭代调试。语言能力也是飞跃性的提高,不仅能在更长的文本中实现逻辑和内容的一致,也能掌握各种复杂话题。
在所有测试中,GPT-4都能击败绝大多数高中生,包括AP和SAT分数。

从基准测试的角度衡量,可以看到下面这张图。
根据Contextual AI去年7月发布的研究结果,AI在语言理解、阅读理解、文字细微差异的解释、图像识别等方面的能力都已经超过了人类表现。
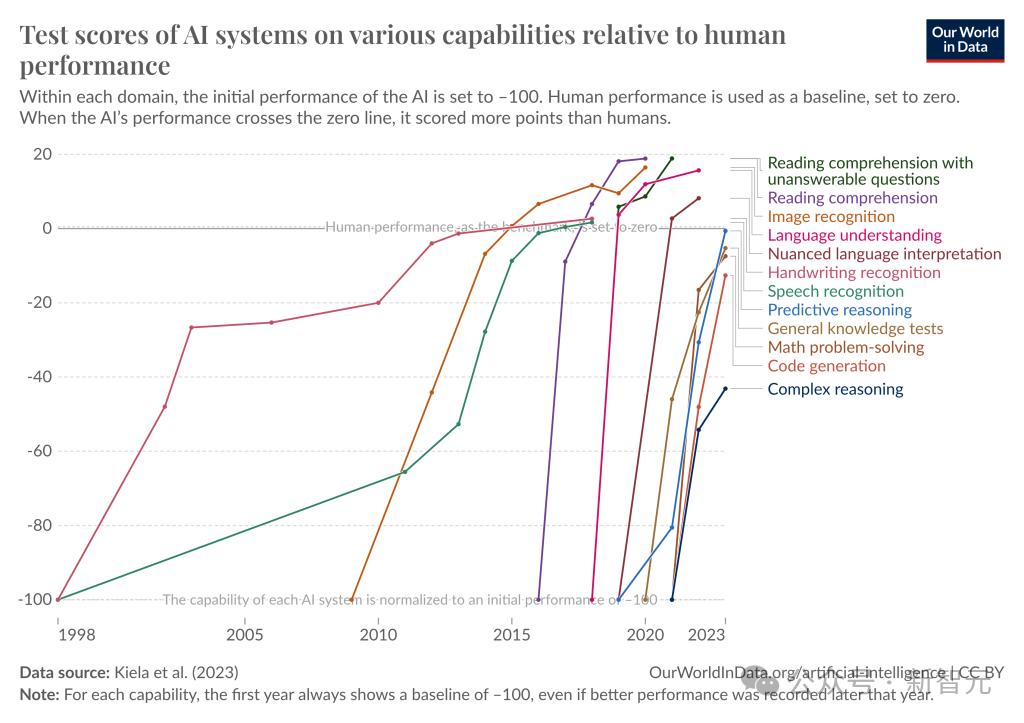
预测性推理、一般性知识测试和解决数学问题等任务上也与人类水平接近。
此外也可以看出,在模型能力增长得越来越快的同时,基准测试愈发捉襟见肘。
过去需要几十年的时间才能达到饱和的基准测试,现在只需要几个月。
2020年,MMLU测试发布,相当于高中和大学的所有最难考试的水平,研究人员希望它可以经得起时间考验。
结果仅仅三年后,LLM就几乎解决了这个测试,像GPT-4和Gemini这样的模型可以获得超过90%的评分。
数学测试也是一样的趋势。
2021年MATH基准发布时,SOTA模型只能正确回答约5%的问题。
当时很多研究者都认为,算法方面的根本性突破才能提升模型的数学能力,未来几年能取得的进展非常微小。
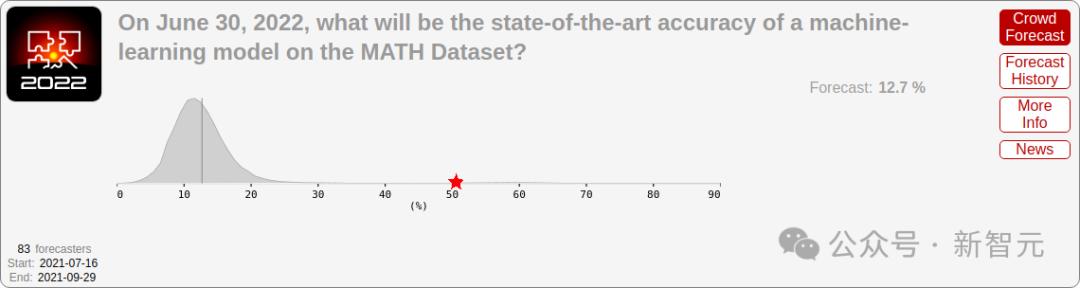
2021年,研究人员对模型未来在MATH数据集上的表现给出了非常悲观的预测
然而,又一次超乎所有人的想象。2022年一年的时间内,模型准确率从5%上升到50%,最近的SOTA可以达到90%。3年前公认难度很高的基准测试,很快饱和。
基准测试似乎也无法跟上模型的速度了。
为了更严谨地评估深度学习的发展速度和趋势,作者使用了OOM指数,即「计算数量级」(order of magnitude)。
不仅要考量模型的算力和算法效率,作者还引入了一种新的概念,「解开收益」(unhobbling gains)。
算力规模
刚刚结束的ComputeX大会上,英伟达、AMD纷纷宣布了芯片年更计划。
这说明了什么?大模型性能呈指数级增长,对算力需求也在不断放大。
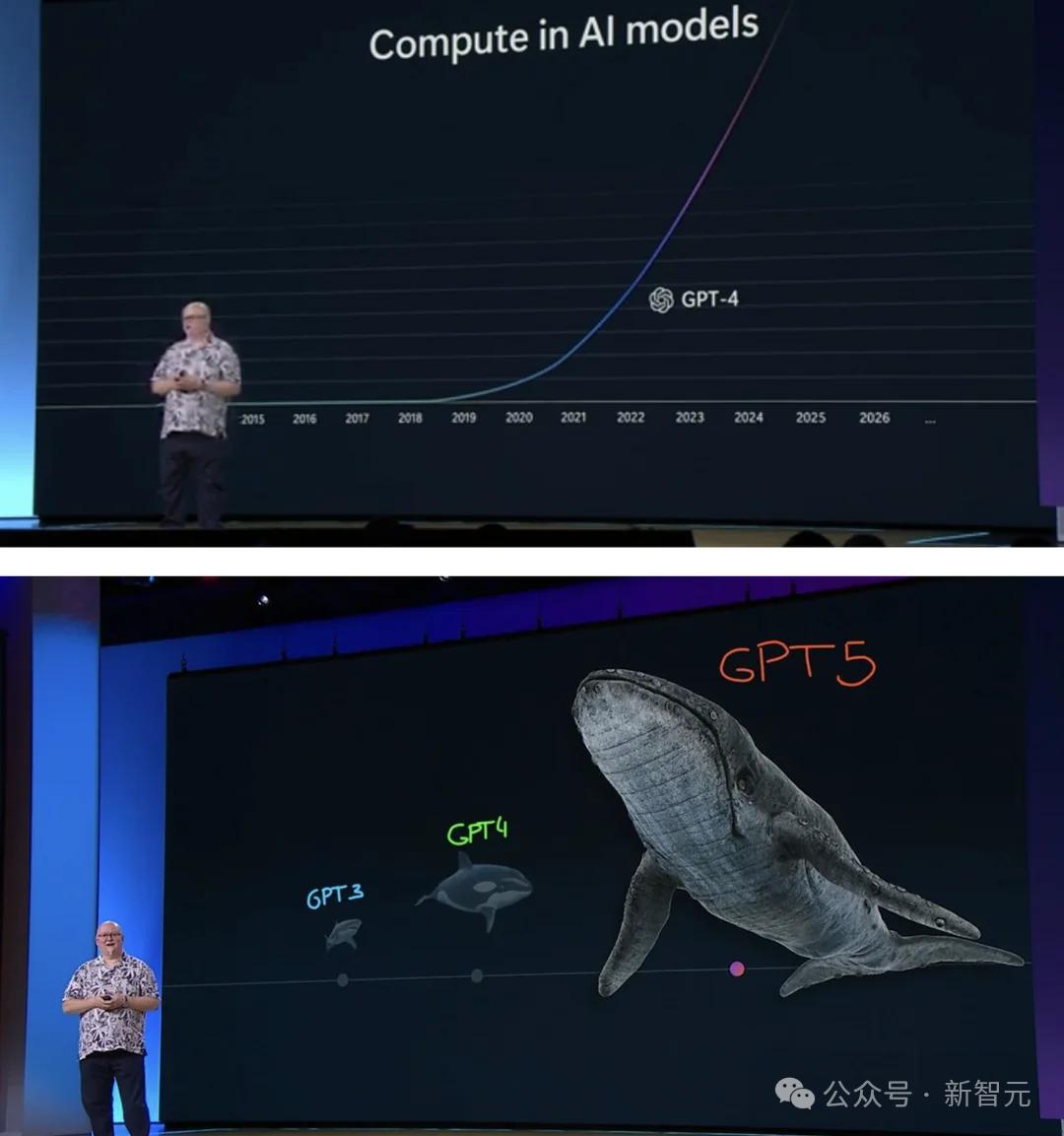
而在微软Build大会上,CTO Kevin Scott更是用海洋动物形象地阐述了,OpenAI模型进阶对算力的吞噬之极。
提到算力增长,很多人的第一反应会认为,这是摩尔定律的延伸。
然而作者指出,事实并非如此。AI硬件的改进速度远远快于摩尔定律。
大模型时代来临前,即使摩尔定律处于鼎盛时期,每10年也仅有1-1.5个OOM的增长。
但现在,每年都有0.6个OOM的增长,比曾经摩尔定律的5倍还多。
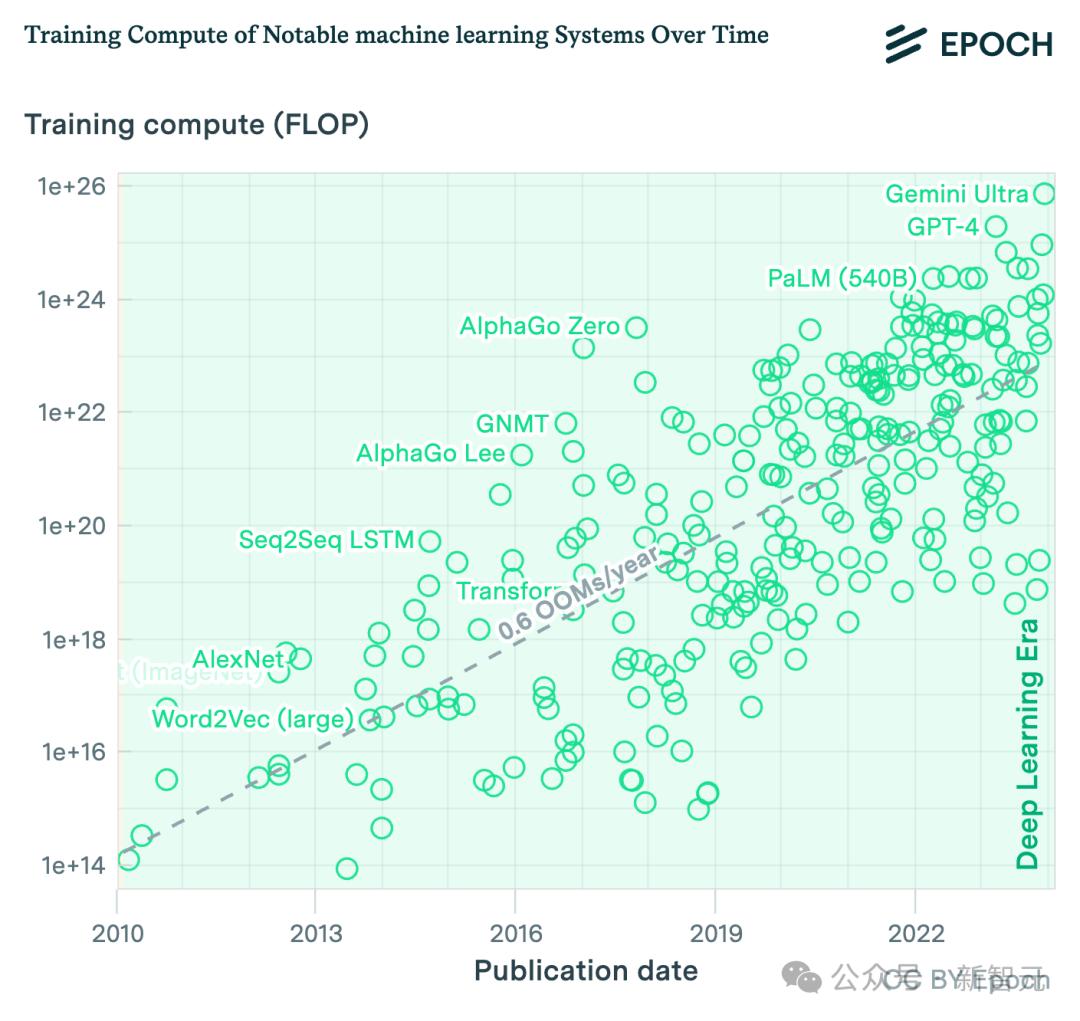
Epoch AI对著名深度学习模型的训练算力进行估算
以GPT系列为例,GPT-2到GPT-3实现了设备的过渡,从较小的实验设备变成了数据中心,一年内增长了2个OOM。
GPT-4延续了这种戏剧性增长,而且从OpenAI囤积芯片的动作来看,这个增长速度会逐渐演变为长期趋势。

这种庞大的增长,并不能主要归因于摩尔定律,而是投资算力的热潮。
曾经,在一个模型上花100万美元是令人发指的想法,没有人会接受;但现在,这只是科技巨头囤芯片、训模型的零头。
过去一年里,科技巨头们谈论的话题已经从100亿美元计算集群转向1000亿美元集群,再变成万亿美元集群上的竞争。
每隔六个月,董事会的计划里,就会增加一个「0」。
作者预估,「在这个十年结束之前,将有数万亿美元投入到GPU、数据中心和电力建设中。为支持AI的发展,美国至少将电力生产提高数十个百分点」。

随着AI产品收入的快速增长,谷歌、微软等公司在2026年左右的年收入可能达到1000亿美元。
这将进一步刺激资本,到2027年,每年的AI投资总额可能超过1T美元。
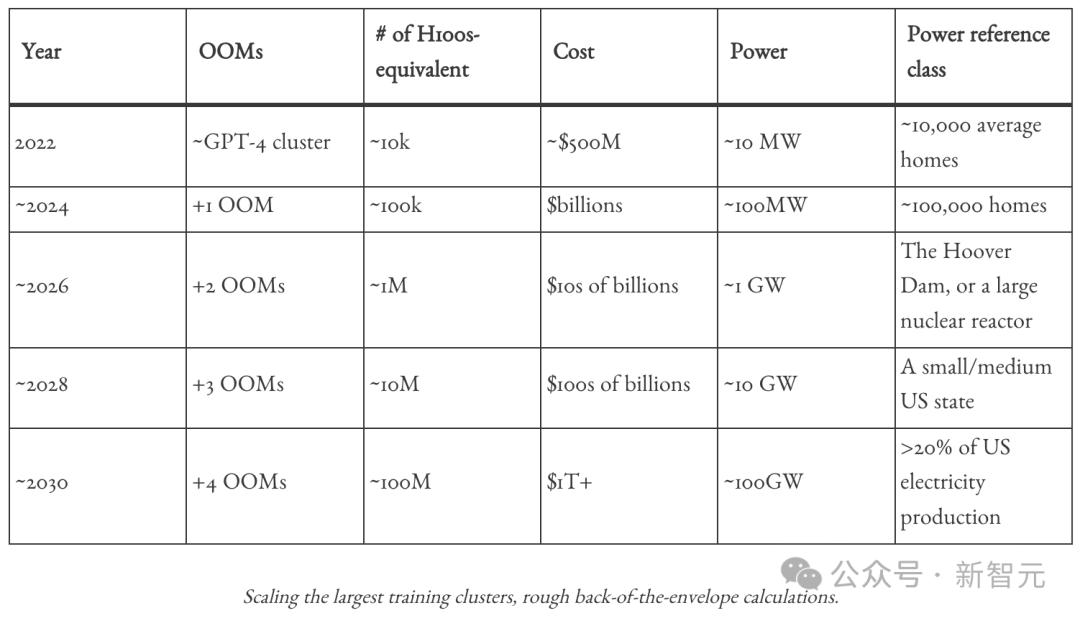
时间线再拉远,到2028年,单个训练集群就需要耗资千亿美元,比一个国际空间站还贵。
而到本世纪末,一个集群就能吞掉1T美元,每年产出上亿个GPU,AI所需电力占美国发电总量的百分比,将从现在的不到5%上升到20%。
算法效率
对算力的疯狂投资带来的惊人收益是非常明显的,但算法进步的驱动力很可能被严重低估了。
比如,很少有人关注到模型推理成本的大幅下降。
以MATH基准测试为例,过去两年内,从Minerva到最新发布的Gemini 1.5 Flash,在MATH上取得50%准确率(一个不喜欢数学的计算机博士生可以得到40%)的推理效率提高了将近3个OOM,也就是1000倍的效率提升。
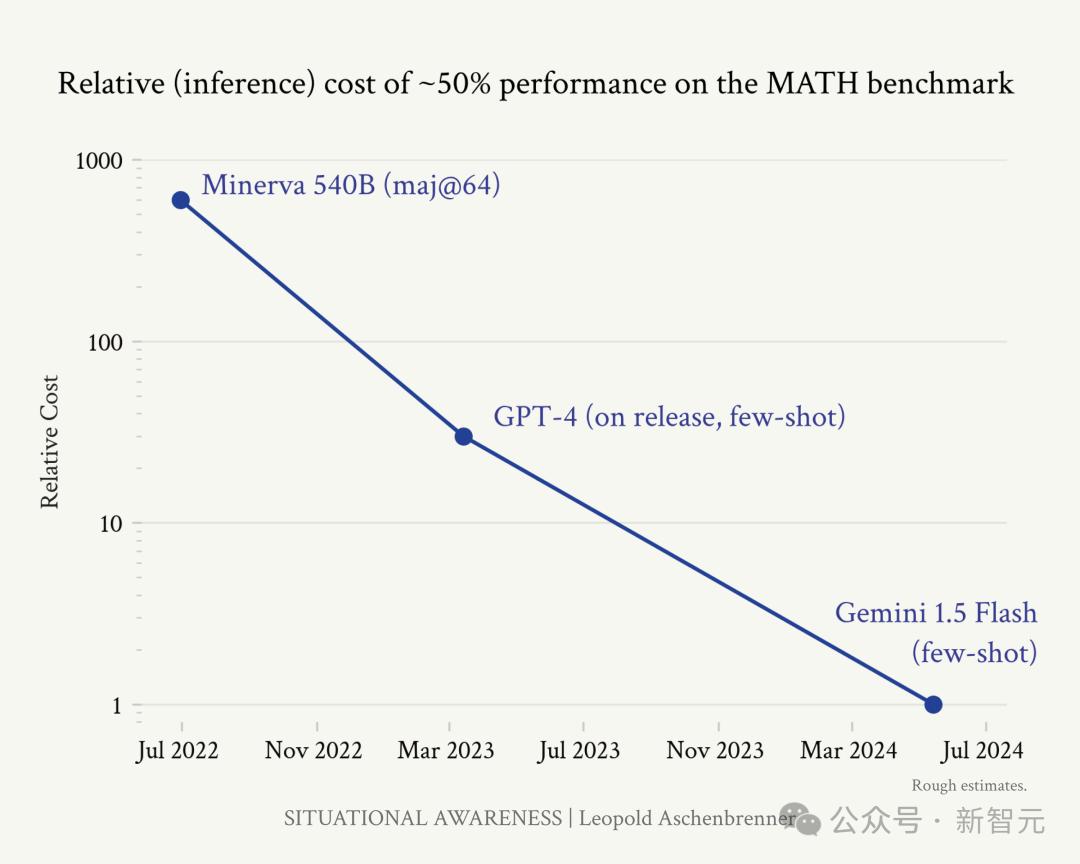
虽然推理效率不等同于训练效率,但这个趋势可以表明,大量的算法进步是可行的,而且正在发生。
从长期趋势来看,算法进展的速度也相当一致,因此很容易根据趋势线做出预测。
回顾2012年-2021年期间ImageNet上的公开算法研究,可以发现,训练相同性能模型的计算成本以近乎一致的速度下降,每年减少约0.5个OOM,而且每种模型架构都是如此。
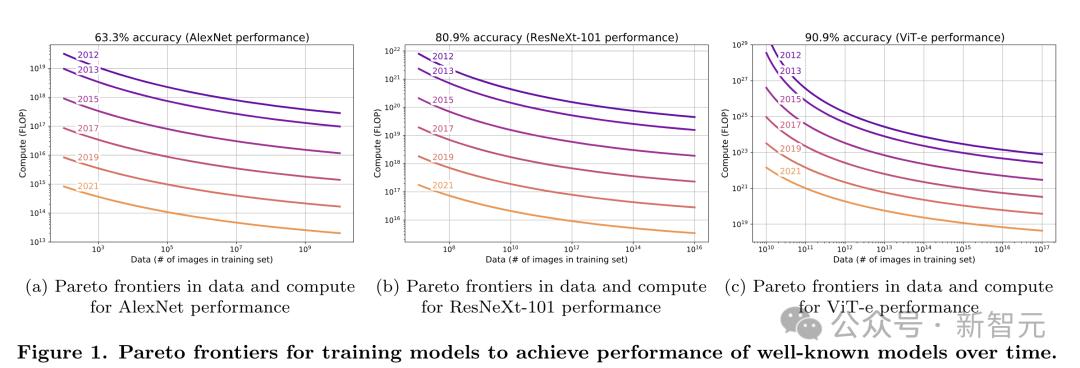
虽然LLM的团队一般不会公开算法效率相关的数据,但根据Epoch AI的估算,2012年-2023年期间,每年算法效率的收益也约为0.5个OOM,也就是在8年时间里提升了1万倍。
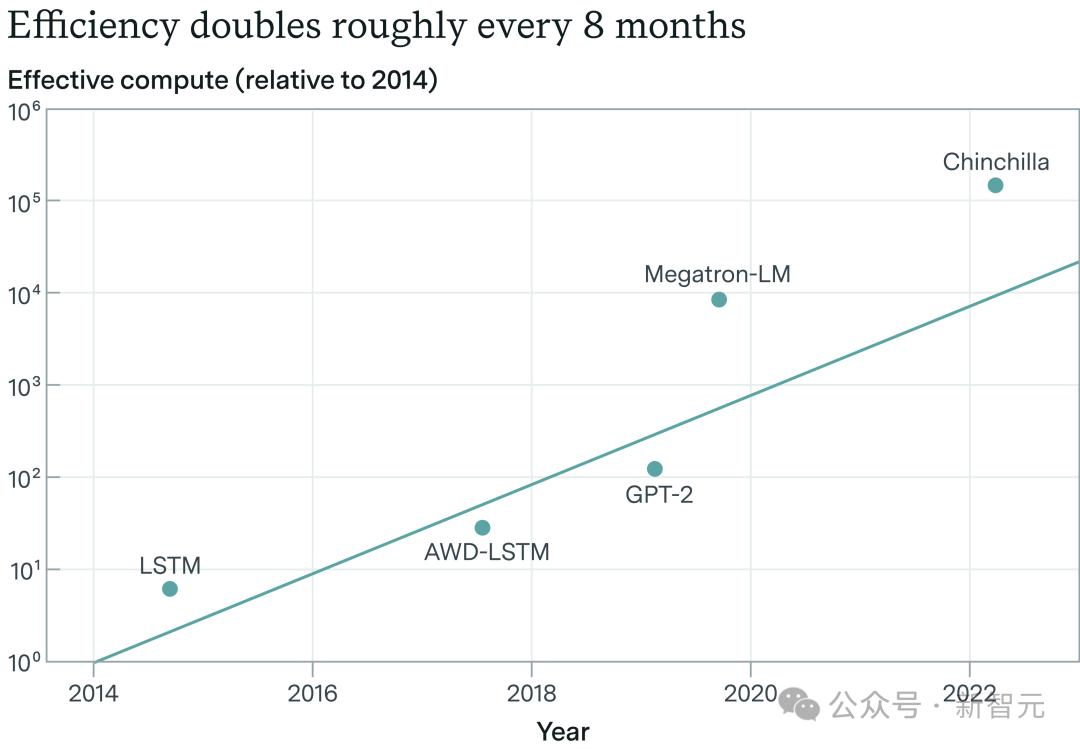
「解开」收益
相比算力和算法效率,「解开」收益带来的提升更加难以量化。
所谓「解开收益」,是指某些情况下模型的原始能力被阻碍了,而通过简单的算法改进可以解锁和释放这些潜在能力。
虽然它也是一种算法改进,但不仅仅是在已有范式内提升训练效果,而是跳出训练范式,带来模型能力和实用价值的跃升。
比如基础的语言模型经过了RLHF,才变成真正可用的产品。InstructGPT论文的量化结果显示,根据人类评分者的偏好,有RLHF的小模型相当于非RLHF的大100倍的模型。
再比如,近年来被广泛使用的CoT可以为数学或推理问题提供10倍多的有效计算能力提升。
上下文长度的增加也是如此。从GPT-3的2k tokens、GPT-4的32k,到Gemini 1.5 Pro的1M+,更长的上下文可以解锁更多的用例和应用场景。
训练后改进(post-training improvment)带来的收益也不容忽视。OpenAI联创John Schulman表示,与GPT-4首次发布时相比,当前的GPT-4有了实质性的改进,这主要归功于释放潜在模型能力的后期训练。
Epoch AI进行的一项调查发现,在许多基准测试中,这类技术通常可以带来5-30倍的有效计算收益。
METR(一个评估模型的非营利组织)同样发现,基于相同的GPT-4基础模型,「解开收益」非常可观。
在各种代理任务中,仅使用基本模型时性能只有5%,经过后期训练可以达到20%,加上工具、代理脚手架和更好的后期训练,可以达到今天的近40%。
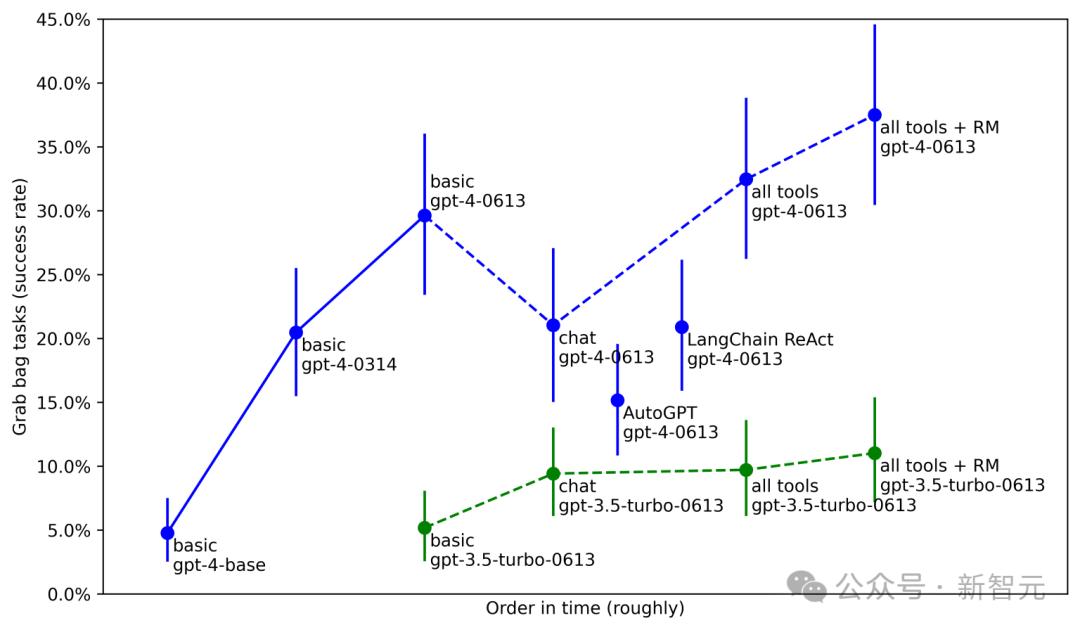
与算力和算法效率带来的单一维度的扩展不同,「解开收益」能够解锁模型能力的巨大可能性,带来「阶梯式」、不拘一格的进步。
想象一下,如果AI可以使用电脑,有长期记忆,能针对一个问题进行长期思考和推理,而且具备了入职新公司所需的上下文长度,它会有多么强悍的能力?
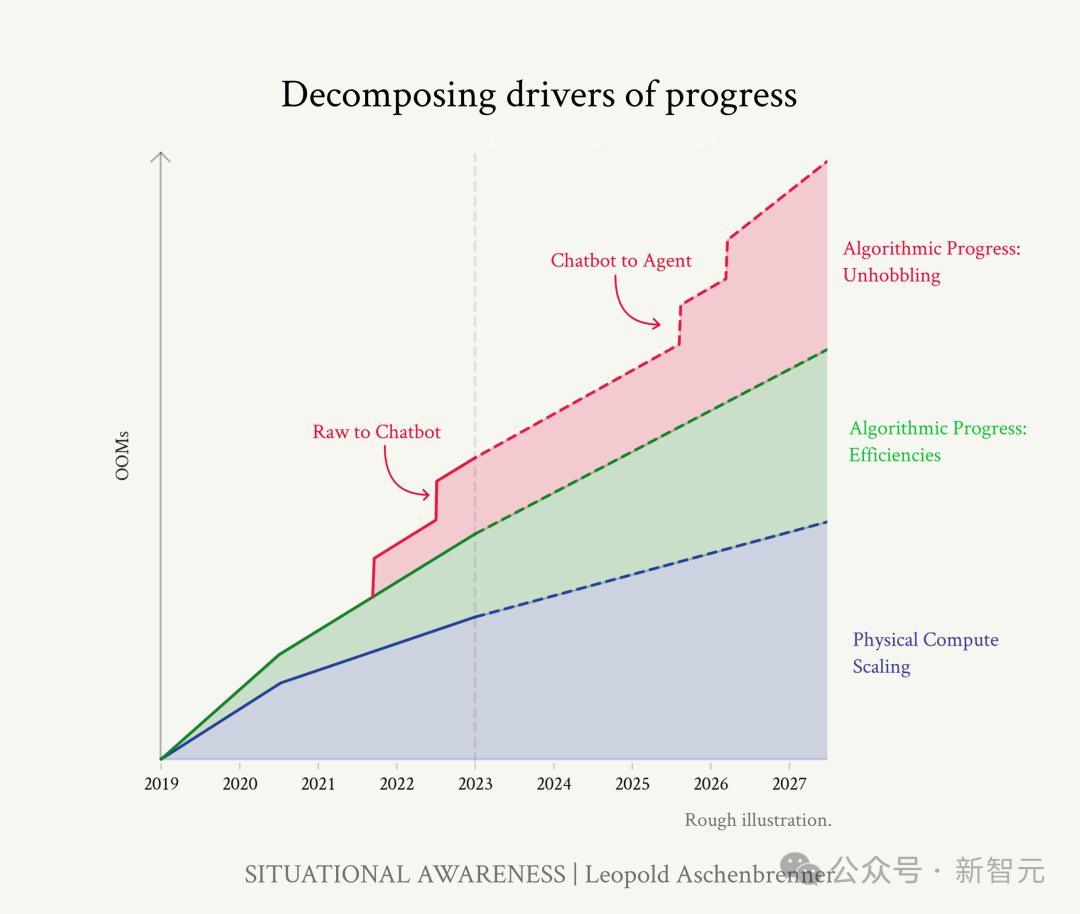
算力、算法效率、「解开收益」叠加
2027年,取代所有认知工作
综合考虑算力、算法效率与解开收益这三个方面的叠加,GPT模型从第2代到第4代,大致经历了4.5-6个OOM的有效计算扩展。
此外,从基本模型到聊天机器人,相当于约2个OOM的「解开收益」。

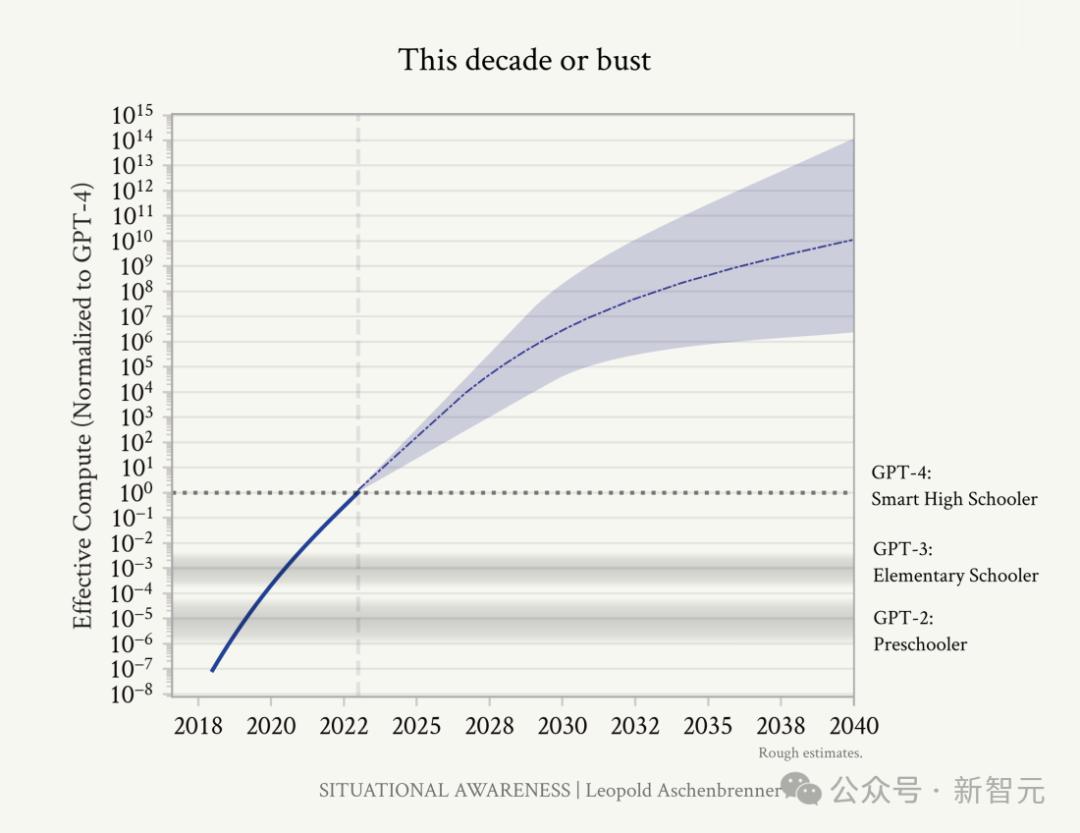
基于这个发展速度,数一数OOM,未来4年我们可以期待什么?

首先,随着计算效率提高,迭代速度会越来越快。假设GPT-4训练花了3个月的时间,到2027年,领先的AI实验室将能够在一分钟内训练一个GPT-4级别的模型。
而且,由于「解开收益」的存在,我们不能仅仅是想象一个非常聪明的ChatGPT,还需要把它看成一个非常智能的、能独立工作的Agent。
到2027年,这些AI系统基本上能够自动化所有认知工作,或者说是所有可以远程进行的工作。
但是作者同时也提醒道,这其中有很大的误差范围。如果「解开收益」逐渐停滞,或者算法的进展没能解决数据耗尽的问题,就会推迟AGI的来临时间。
但也有可能,「解开收益」释放了模型更大的潜能,让AGI的实现时间比2027年更早。
虽然这篇文章有比较全面的论据,但「2027年实现AGI」的结论还是引发了不少网友的质疑。
将GPT-4的智力水平类比成聪明的高中生,很难让人相信。

也没有谈到一些关键问题,比如当前LLM最大的挑战之一——幻觉,这也是AI实现自动化工作的巨大障碍。
有人指责作者,将曲线外插和巨大的误差范围包装成一份技术分析。

也有人指出,文中经常提及的「有效计算」是一个非常模糊的概念,没有进行严谨准确的定义。

抛开2027年这个颇有噱头的结论,作者的论证过程至少可以给我们一个启示——很多情况下,AI的发展速度会超出所有人的想象。

GAN网络从2014年到2018年的进展
作者简介
Leopold Aschenbrenner本科毕业于哥伦比亚大学,大三时入选Phi Beta Kappa学会,并被授予John Jay学者称号。
19岁时,以最优等成绩(Summa cum laude)毕业,作为毕业生代表在典礼上致辞。

本科期间,他不仅获得了对学术成就授以最高认可的Albert Asher Green奖,并且凭借着「Aversion to Change and the End of (Exponential) Growth」一文荣获了经济学最佳毕业论文Romine奖。

Leopold Aschenbrenner来自德国,现居风景优美的加利福尼亚州旧金山,志向是为后代保障自由的福祉。
他的兴趣相当广泛,从第一修正案法律到德国历史,再到拓扑学,以及人工智能。目前的研究专注于实现从弱到强的AI泛化。
他最近离开OpenAI后计划创办一家AGI领域的投资公司,已经获得了Stripe创始人Collison兄弟以及GitHub前CEO Nat Friedman的投资。






 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的