
从OpenAI烧起来的价格战大火,迅速蔓延到大洋彼岸。
5月13日,OpenAI在发布GPT-4o的同时,将其API价格调低50%,每百万tokens的输入价格降至5美元(折合人民币约35元),抢跑大模型价格战的第一棒。
随后半月,国内各家大模型厂商掀起了降价潮。阿里旗下9款大模型降价后,百度随即宣布文心Speed和文心Lite两款模型免费。紧接着,智谱GLM-3-Turbo模型、字节的豆包大模型、阿里通义系列模型等也纷纷将百万tokens的输入价格从100元左右降至1元左右。
降价背后的根本原因,是大模型厂商对商业化落地的迫切。但看似激烈的价格战很难缓解行业困局。
“本轮价格战的主要参与者都是云厂商,几家头部大模型公司有动作、但并不激进,毕竟现在能大批量采买算力和模型服务的企业仍是少数。”关注芯片产业的投资人胡杨告诉硬氪。
说到底,企业跑在大模型上的应用要落地,靠的是海量训练和无休止迭代,仅推理token降价并不能解决训练和部署端高昂的算力开销。算力焦虑然挥之不去。
在这一背景下,集成软硬件服务的算力一体机开始吸引关注。
算力一体机结合了高性能计算的硬件和优化的软件算法。大厂价格战只是给行业提供价格便宜甚至免费的API,算力一体机将所有计算资源集中到一台设备上,思考的是如何降低模型算力、部署成本和技术门槛,优化性能等问题,针对没能力自己建数据中心、开发大模型的普通企业。
长期的算力焦虑一定程度上限制了国内AI产业的规模化发展。从技术到生产力的转化,以算力一体机为代表的“开箱即用”产品,或许能成为企业尝试大模型应用的关键一步。
大模型应用的最大瓶颈
算力部署是一场需要金钱灌注的持久战。
当前全球GPU芯片缺口巨大,英伟达一家无法满足所有AI大模型训练、推理的需求。英伟达以外,其他多元异构GPU也在快速发展中,算力生态呈分散态势。2018年1月到2021年1月期间,参数量每18个月增长达高340倍。对比之下,2016至2021年的GPU内存增长量,每18个月仅为1.7倍。
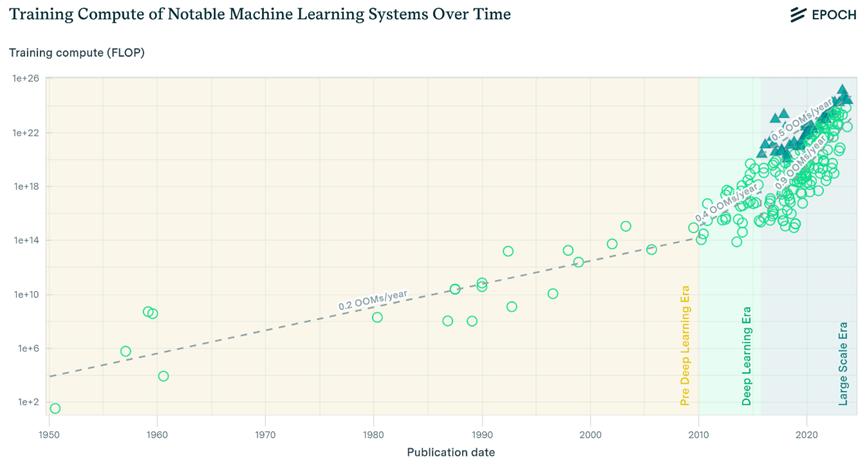
随着时间推移,模型参数量增长
英伟达、AMD、英特尔等单芯片算力增长,赶不上大模型参数量、训练数据量所需的算力增长。
对于能拿到算力的公司,摆在眼前的就是成本问题。
Meta曾明确提到,LLaMA需使用到2000个A100 GPU,3周1次训练,其单次训练成本为500万美金。百川智能CEO王小川也曾表示,每1亿参数对应的训练成本约为1.5万到3万元,由此计算,一个千亿级参数的模型的单次训练成本约3000万元。模型越大、GPU开销越大。
从传统产业和中小公司的视角来看,他们的需求很明确:高性能低功耗的算力、稳定且响应迅速的模型、保证数据安全。
但这些企业风格相对保守和现实,早期阶段就很重视模型应用在具体业务中ROI表现,前景不明朗时,他们不愿贸然投入。
如果要及时见效,场景应用时,常见的做法是基于通用底座微调后,做私有化部署。然而, “这种方法很多时候对企业来说是个不小的负担。”在2024年SusHi Tech Tokyo的会场上,「Avalanche Computing」CEO陈杰告诉硬氪。
展馆中,关于产业智能升级、AI融合的讨论无处不在。429家参展企业,随处可见与AI相关的物料,从底层架构、模型训练、AI Agent工具、服务器设备硬件到芯片等等,超过70%的公司展示着自家与生成式AI的关联。
成本和算力难以两全时,算力一体机或许是个突破口。
以「Avalanche Computing」为例,其主营hAlsten Al低代码工具和Althena终端系统平台,提供软硬件一体化服务。
其中,终端系统平台Althena是一个算力一体机,可提供离线模型服务,其支持英伟达多款设备,搭载了目前市面上主流的开源大模型,包括LLaMa3、Mistral AI、Gemma等,可以降低企业开发大模型的技术门槛。
进入使用环节,企业可以选择运行由HAIsten AI训练所得的模型,并对模型提问。测试显示,在离线状态下,该模型可在2-3秒内生成答案;同时,企业也可以在连接网络后,自由更换想要调用的大模型。
一个Althena算力一体机可以支持2-3人同时使用,售价最高1.5万美元/年(折合人民币10.9万元/年)。而一台英伟达DGX A100服务器,其发售价为19.9万美元(折合人民币约145万),以目前常见的四年折旧期计算,每年42.5万元。
可以看到,价格仅为DGX A100四分之一的Althena算力一体机,极大降低了大模型训练和部署的成本开销。

英伟达DGX A100服务器
保障企业安全,降低开发门槛
当前,业内正探寻多种路径以优化算力资源的调度,包括MOE(混合专家模型)架构、高性能AI计算系统、算力一体机等。
其中,算力一体机通过定制的硬件架构和优化的软件系统,具有高兼容性、高稳定性、高扩展性和高算力利用率。对于前期算力需求不大的传统产业客户和中小公司来说,在一定程度上能满足其处理数据和复杂计算任务的需求。
据硬氪了解,除了考虑算力成本,大模型行业落地还存在两大难题,分别是企业安全和开发应用门槛。以日本市场为例,「Avalanche Computing」目前所接触到的客户以传统制造业为主,陈杰告诉硬氪,“这类企业非常强调数据私密性,担心机密外泄,他们的知识图谱和数据库往往会选择keep in house(即保存在公司内部)。”
算力一体机采用了边端私有化部署的方式,是保护企业数据隐私安全的有效手段之一。它在硬件上整合了通用算力、智能算力、存储、网络、安全,企业不需要自建机房,可以进行本地化的快速部署。
其次,企业安全问题也涉及到系统的稳定性。此前国内云厂商宕机事故频发,不仅自身重要业务停止运行,更影响到许多客户企业产品崩溃,导致一系列技术问题发生。即使是自建单机房,一旦机房或网络发生故障,业务可靠性也无法保证。
算力一体机的离线服务,在发生突发状况时,能维持系统的稳定运行;同时降低了企业的使用门槛,用户只需要将相关数据打包并上传至一体机内,并选择想要使用模型,即可低成本收获一个部署在企业内部的私有大模型。
最直观的体现是,过去企业调试一个模型,仅接⼊、验证等至少需要⼀周时间。现在用算力一体机,半天就可以跑通⼀个模型并看到使用效果。
但需要注意的是,当前基于通用大模型,并不是企业将数据库输入模型训练后、就能得到专业的结果,仍需要不断地使用并迭代。由于推理所需的算力开销往往无法预估,Althena算力一体机的租赁式方案灵活,提供弹性的推理资源,对早期需求不多的企业可选择小量采买、后期起量后再增加设备。
大模型行业正进入价格内卷期,但在这波热潮之下,同时满足算力充足、价格适宜,并兼顾安全的产品仍未诞生。就目前来看,对于还处在早期观望的企业而言,扮演着基础设施角色的算力一体机,也许是种解答。



 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的