
大模型火火火火火足两年了,如今的大模型江湖,是什么模样?
摊开全球画卷,OpenAI依旧在通用大模型领域一骑绝尘,但整个生态百花齐放——有擅长长文本的Claude、开源王者Llama、开源新秀Mistral、画图王者Midjourny……
到底什么才是评估大模型的第一要义?参数、规模、价格、榜单排名?似乎都还不够,或许只有能脚踏实地在人们的生活和工作里用上大模型,并且够稳定、不出错,才是千千万万企业和用户最为关心的话题。
对如今的大模型领域,必须要再度搬出那句程序员的老话:Talk is cheap,Show me the code。
用起来,才是王道。
现在,打开字节跳动旗下的AI“扣子”平台,就能看到成百上千的bot,正在参与一场火热PK。
从2024年2月1日上线以来,扣子已经接入了多个国内知名大语言模型,包括豆包、通义千问、智谱、MiniMax、Moonshot、Baichuan等等——宛如琳琅满目的大模型“货架”,无论是哪家大模型,小中大尺寸,应有尽有。
无论是学英语、编程、写文案,算命,民间高人们在这些模型上开发出来的应用,可以说是五花八门。但到底怎么样才能在这些场景用得最好?
扣子模型广场简单直接地提供了对比评测的平台。
如果你是一位小红书博主,就可以直接打开扣子里的小红书文案生成器,搭载两个不同的大模型,实时测试比对。
两个Bot都使用了同样的Prompt和插件,但无论是响应速度还是返回的内容,在实时测试里,效果对比一目了然。
如同游戏一样,扣子模型广场提供了多种有趣的玩法,包括指定Bot对战、随机Bot对战、纯模型对战。
比如,在随机对战中,系统就会随机选择一个Bot,进行模型对战。这适用于评测模型在任意业务场景下的文本生成、技能和知识调用等能力——PK的两个模型都是匿名的,基于 Bot 的Prompt、工作流、知识库等能力配置,回答用户的问题。
PK则过程完全向用户公开。前来观光的用户,可以通过模型对战与两个隐藏了模型的Bot实时对话,并根据模型的回答进行投票。投票结束后,广场才会揭秘具体的模型。
PK也不只是纯看用户投票。结果公示后,用户则可以展开结果页面,查看两个模型的详细配置,包括生成多样性、生成随机性等配置参数。
从2022年年底ChatGPT爆火,到如今Sora、Midjourney等多模态模型的成果震撼人心,到现在的扣子模型广场的推出,无疑是大模型生态日渐成熟后,向应用层的“上探”——人们不再讨论数字,而是开始考虑是否可用。纵观整个AI领域的发展脉络,这也是大模型新技术走向To C化的重要一步。
01. 大模型爆火两年后:这么近,那么远
回溯人类科技史,大概很少有技术像大模型一样,以狂风骤雨般的速度让全社会都形成共识:这是一项能够切实提升生产力,改变未来的新技术。
从ChatGPT背后搭载的GPT-3.5,到GPT-4和最新的GPT-4o,过去两年中里的通用大模型经历了过山车一般的发展速度。大模型、芯片厂商还在共同大炼模型,试图探索Scaling Law(缩放定律,不断扩大参数规模和数据量,能得到更强的模型能力)的极限。仅仅以参数量来衡量,GPT-3.5参数量是1760亿,这还是一个闭源模型;到了今年,人们所能用到的最先进开源模型Llama 3,参数量就已经超过4000亿。
更大的参数、数据量,就像土壤,是模型能力的基础,但土壤上能够长出什么样的应用——是苔藓还是参天大树,考验的是模型“有多聪明”。
动辄数千亿参数的模型可以展现技术前沿,如今的模型创新者们正在努力把模型做小。这相当于将模型“蒸馏”,让更小的模型能够拥有更强大的性能。2023年9月发布的Mistral 7B(70亿参数)就是小模型派的代表,能够打败130亿参数的Llama 2模型。
到了2024年,“小模型”的趋势更加势不可挡。Meta旗下的Llama 3发布后,旗下80亿模型(8B)的性能,就比上一代的Llama 2 700亿参数模型还要强,因此在文本、数学、编程方面的能力大大增强。
究其原因,这是由于Llama 3“学习”的数据密度足够丰富——用了 15 万亿 Token 的训练数据,这比Google旗下的Gemini同等模型多学了一倍还不止。
但尽管如此,一个现实是,现在的大模型依旧面临着“隔岸观火”的尴尬境地:在开发者圈内,模型进展日新月异,性能更强,用例也越来炫目;但在对岸,则是“看在眼里急在心里”,困惑于如何用上大模型的普通用户。
实际上,大模型离人们的工作和日常生活的距离还很远。数据就有所印证——MIT的一项研究显示,但就计算机视觉(CV)这个领域来看,今天能够自动化的工作,占美国经济中占工人薪酬1.6%的任务(不包括农业),但只有23%的薪酬任务(占整个经济的0.4%)按自动化是更划算的。AI如今在人类工作流中所占据的比例,还非常小。
对普通的C端用户来说,AI应用更多是一个“一轮游”的存在。过去两年中火爆的AI应用,很多迎来大批试用、试玩的用户之后,真正留下的日活、周活用户寥寥无几。真正核心受众,停留在专业开发者、垂直领域的专业人员(如设计师、运营、写手等等)。
一方面,这是由于底层的通用大模型能力还需要不断提升,如今的模型还有幻觉等等可控性问题,都未得到很好地解决;此外,模型的记忆能力还处在比较小的阶段,还无法真正做到记住用户的喜好、习惯等等,更复杂的交互也无从谈起。
这导致如今的各类AI应用能落地的地方,集中在容错率较高的创作类场景中,如写文案、画画、对话等等,或是基于语言大模型的简单游戏。
更重要的是,交互层面的门槛尚处在高位——和大模型对话,对话深度有限,还需要用户研究怎么写Prompt(提示词),数据训练也有不小的理解门槛。企业端用户想要用上大模型,更是想要跨越选型、微调等工作。
一言以蔽之:大模型,依旧有着艰深的理解和应用成本。
所以,真正到了辅助决策类——企业核心工作流中,大模型其实还没办法达到可用状态。比如,根据数据分析厂商“九章数据”的统计,在数据分析场景里,用大模型生成SQL(结构化查询语言,一种数据库的核心语言)准确性约在70%左右,但剩下的30%,还需要专家人工手动检查,这就失去了以AI提升效率的意义。
大模型和用户侧,现在就如同渐近线一般,需要找到能够在技术和场景上相匹配之处,让用户真正“用起来”。在刚结束不久的“AI届春晚”智源大会上,智源研究院院长王仲远就表示:“国产大模型已经开始无限接近 GPT-4,这意味着基础模型已达到可用的状态,但当它达到可用状态开始赋能千行百业,进入各行各个垂直领域,还需要找到更好的产业生态和合作模式。”
02. AI应用,爆发前夜
很多人会将大模型的爆火,比作如同移动互联网那样的历史机遇。这样瞬间可唤醒很多人的记忆——如今层出不穷的AI应用,就和移动互联网时期的App混战,如出一辙。
如果参照历史规律,从个人电脑带来的PC互联网时代,再到移动互联网时代,每一次技术革新后到大量应用出现,几乎都需要经过2-3年以上的时间——2007年,苹果推出iPhone 1,定义了移动互联网时期的交互形式,直到两年后,Uber、Whatsapp、Instagram等产品才依次出现,成为席卷全球的应用。
这期间发生了什么?底层的技术变革继续进行,不断让成本下降到可以商用的水平,大量应用创新才得以出现。这会进一步倒逼基础设施的变革——云计算、大数据等行业,正是由于大量移动终端增加,人们在线时长也在不断增加。
如今的AI领域,也同样站在了技术革新到应用繁荣的临界点上。
伴随着大模型技术革新,应用创新已渐有燎原之势。2023年,GPT-4发布后,OpenAI随即在11月上线GPTs商店,开发者用简单的套壳,就可以马上做出各式各样的应用,短短两个月内,办公、设计、生活、教育、科研、编程等各个领域超过300万个GPTs,如同雨后春笋般出现。
而前不久的WWDC大会上,苹果正式官宣与OpenAI的合作——将把ChatGPT集成到iPhone、iPad和Mac设备中——宛如当年的App Store重现。
据Gartner技术成熟度曲线显示,现在,大模型领域的生成式AI(Generative AI)和基础模型(Foundation Models)都处于膨胀的巅峰期,再往下走,就是应用爆发时期。
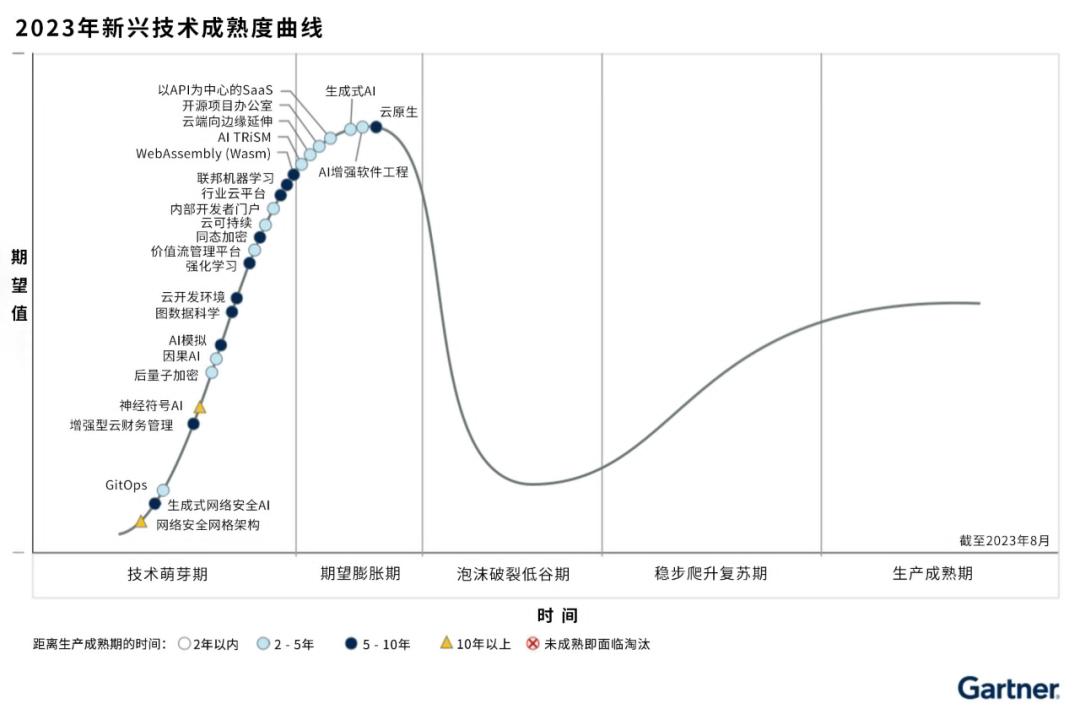
来源:Gartner
不过,但中间还有许多工作需要完成。大模型技术浪潮爆发后,从底层的芯片、中间层的Infra架构等等,都在密集而迅速地进行一轮变革:GPU芯片需要加强推理效率,而软件中间层则需要承接大模型的大规模推理和应用需求,在算法层面降低调用成本。
AI的难,在于大模型本身的技术复杂性上,而在终端设备、大模型等“平台级”基础设施和前端应用之间,如今会更需要“送水人”的力量——“扣子”等AI应用开发平台,现在担当的就是这样一种角色,让大模型的能力顺利输送到使用场景之中。
比如,对于一位0编程经验的用户来说,现在开发AI应用几乎已经没有难度——和“扣子”进行交互,短到仅需要一句话即可。
至于用什么模型、如何使用模型,也无需了解艰深的专业名词才懂得模型的性能几何。“扣子”的Home Bot就像一位手把手带你的老师,如何使用模型、平台上有什么现成的Bot可以使用,扣子都能给出相应的建议。
再到开发过程中,“扣子”现在就已经像是一个开箱即用的工作台一样,给用户提供了丰富的组件选择——插件、工作流、图像流、触发器等等。如此一来,用户开发的,就再也不局限于简单的套壳应用,而是可以通过联动api、封装好的模块等等,完成复杂任务的执行。
从去年年底上线以来,“扣子”平台上就已经有不少有趣的用例。比如,一位汽车发烧友,为了解答身边诸多好友的选车问题,就使用“扣子”的工作流功能,添加了 5 个节点,最后实现根据用户需求搜索车型、对比参数,到最终输出图文并茂的购车建议。
在5月15日的火山引擎FORCE原动力大会上,曾经展示过一个案例,一位五年级学生开发出了一个名为“青蛙外教”的智能体,并且已经将其分享给了同学朋友们一起使用。
从某种意义上来说,“扣子”等AI应用开发平台的最重要意义,就是将原来AI应用覆盖的开发者群体,向外延展到所有主流用户当中。在大模型本身还无法解决端到端的问题时,发动所有人的力量来开发各式各样的应用,才能让大模型生态加速发展。
而“模型广场”这样的PK形式,更是向市场发出了宝贵的信号:对于大模型这类更强调“因地制宜”,擅长解决智力密集型需求的技术而言,盲目刷榜、比拼参数已经没有意义。模型厂商和开发者,都应当将注意力放到一个个的应用场景中——设身处地地了解用户反馈,才可能真正找到这一阶段的PMF(Product Market Fit)。
03. 等待下一个Killer App
如果将国内大模型火热的这两年,划分出演进的历程:前半程,所有人焦急于大模型什么时候可以赶上GPT-3.5,而从2023年下半年开始,话题陡然转变成了:超级应用何时到来?
这种讨论在2024年上半年达到顶峰。市场分化出两种截然不同的态度——不少开发者相信,随着模型规模扩大、智能水平提高,应用能力就自然会发展出来,因此需要集中精力、资源投入到底层大模型中;而另一面则更现实主义——做大模型过于昂贵,试错成本太高。有投资人觉得,最好的方式是“见好就收”,寻找马上就能商业化的场景。
两种态度所聚焦的问题,都是AI应用。
近期,大模型圈内的不少动作,正在加速AI应用的落地进程。就在5月,大模型领域刚刚迎来一次狂风暴雨一样的降价潮——包括智谱、Deepseek、豆包、阿里、腾讯、讯飞在内的主流大模型厂商,都宣布了一轮模型降价。
就以字节旗下的火山引擎为例,5月,豆包大模型矩阵集体降价。现在,豆包主力模型在企业市场的定价就降至0.0008元/1000 Tokens,比行业价格降低99.3%。相当于,用户用1块钱,就能处理3本《三国演义》。
将模型价格打到地板价,固然有市场竞争考虑,但更核心的着眼点,其实还是扩大开发者群体——开发AI应用的试错成本太高,导致长期以来,真正尝试做AI应用的人群太少。但在模型降价后,开发一个模型可能只需要百元、千元级别。以往对AI应用的开发顾虑,已经不再是问题。
反过来说,AI应用供给增加,受众扩大,也会反哺到模型的开发当中。“用户规模的扩大,也将提升大模型的性能。”火山引擎总裁谭待表示。大的模型使用量,才能打磨出好模型,也能大幅降低模型推理的单位成本。
类似的“好信号”还有不少。进入2024年,多模态模型的进展同样令人欣喜——无论是国外的Sora、GPT-4o、还是近期国内Dreamina、可灵等多模态模型爆火,都彻底点燃了用户对视频、图像领域应用的兴趣。破圈的AI换脸、AI翻译、虚拟人跳舞等玩法越来越多。这背后,都离不开多模态的技术突破、模型推理成本的降低,以及中间层的逐步完善。
相对应的,现在的“扣子”平台也已经匹配上AI技术普及的脚步。在近期的更新中,扣子就已经开始支持存储重要内容为关键变量、数据库——相当于给Bot外挂了一个记忆模块。而在交互体验上,“扣子”也支持配置开场白、用户问题建议、快捷指令、背景图片、语音等等,还支持卡片格式输出形式。
简单来说,如果用户现在想要开发一个能翻译、像真人一样讲话的虚拟人,操作也已经非常简单——在扣子上选择合适的通用大模型,就可以简单训练出一个会说话,而且交互非常真实的AI助手。并且,“扣子”可以将构建的 Bot 直接发布到飞书和微信等平台,无缝嵌入到各类生产力工具中。
可以预见的是,随着AI应用落地门槛进一步降低,新一轮市场竞赛会迅速开始。这将让市场跨过这一段尴尬的“应用真空期”——只有真正让AI切实地融入人人可感知、可使用的产品之中,才可能消弭许多焦虑、矛盾,或是令人不安的未知状态。
而眼下,那句程序员群体的老话,或许应该改成:Talk is cheap,show me the CozeBot。



 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的