

做to B,向钱看。
to C业务狂飙大半年的Kimi,开始在B端发力了。
八月尚未过半,两则直接关联其商业化进程的消息,在市场中传开:
二日,Kimi母公司月之暗面官宣Kimi企业级API正式发布。相较于覆盖to C需求的通用模型,企业级模型推理API有着更高等级的数据安全保障和并发速率,用以支持企业内部的复杂工作流和大规模的数据处理需求。
五天后,公司再次放出商业化动作,宣布Kimi开放平台的上下文缓存Cache存储费用降低50%,由10元/1M tokens/min降低至5元/1M tokens/min,价格生效时间为2024年8月7日。
这项技术实际上早在在7月1日就已通过开放平台启动公测,通过预存那些可能会被反复引用、频繁请求的文本或数据等信息来给模型推理过程“降本增效”。
Kimi现今在B端谋求AI变现的动作,绝非此前应用内上线“打赏功能灰度测试”那般仍有试探意味:
从企业级解决方案,到具体场景优化,再到价格调整,月之暗面显然是有备而来。
大模型应用,向钱看
圈内关于大模型应用的立场,在技术落地日渐密集的2024年清晰分成了两派。
七月初在上海举行的世界人工智能大会(WAIC)上,手握目前国内最大规模AI应用访问量的百度CEO李彦宏在演讲中谈及了他对大模型应用的看法:C端当然要做,但大模型更有成果的应用场景仍在B端。
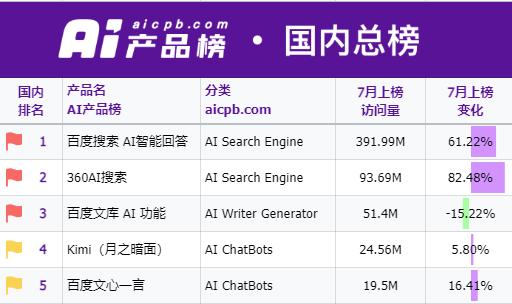
图源/AI产品榜
李彦宏认为,在AI时代,“超级能干”的应用,即那些能够深刻影响产业、显著提升应用场景效率的应用,其价值或许更为重大,它们所创造的整体价值远超移动互联网时代的某些“超级应用”。
未来在医疗、金融、教育、制造、交通、农业等领域,都会依据自己的场景的特点、独特经验、行业规则及数据资源等,定制化地开发出做出各种各样的智能体。将来会有数以百万量级的智能体出现,形成庞大的智能体生态。
这种打法,可以算作现阶段BAT等科技大厂的代表。
从硅星人统计的大模型相关项目中标情况来看,百度今年中标了包括医疗、金融、能源、环保和交通等多个领域的共计17个项目,其中不乏大型国企以及各行各业的头部公司,金额也基本在百万甚至千万级别。
而初创公司代表,像百川智能王小川、月之暗面杨植麟,过去给外界的印象一直是坚定的to C支持者。
AI助手百小应的发布会上王小川就曾表示,to B业务并非百川主要仰赖的商业模式,在美国做to B是好生意,但国内市场C端比B端“大十倍”。
月之暗面创始人杨植麟虽然没有在公开场合过多谈及公司的变现,但也在几个月前上海创新创业青年 50 人论坛的演讲中表示,得益于Transformer架构的提出、半导体产业发展,以及互联网为AI积累下来的大量数据,在世界上可能“第一次出现了这种 AI to C 的机会。”
对于是把Kimi做成to C的AI超级应用,还是把名号打响后多点布局,杨植麟留过活扣:我们to B倒也不是说完全不做,但是我们可能最主要的肯定还是会去聚焦和发力这个C端。
大概是研判时机已到,坚持to C许久的月之暗面,终于对to B“真香”了。
Kimi to B:技术和市场都已成熟
从最浅表的层面来说,做to B解决方案和之前在C端的Kimi相比,需要解决的首先一个问题就是:
对于付费玩家,你的服务器不能有事没事就宕机。
算力规模是个绕不开的话题:月之暗面用一年时间,把Kimi干到了大模型赛道内流量和使用量的顶流(部分统计显示,七月份Kimi和文心一言是国内唯二月活超过千万的主流大模型),但毕竟仍是初创公司,资源比起大厂不会特别富裕是显而易见的。
很少听说文心一言、通义千问出现用户高峰导致算力不足的情况,但经常用Kimi的用户想必或多或少都被算力墙挡住过几个回合的问答(最近似乎好些了)。
而企业客户如果将Kimi作为常用的生产力工具,那么企业级API的服务器就必须保证的稳定性和可靠性,确保在高负载情况下可以正常运行。
结合此番降价的上下文缓存技术来看,除了随着业务体量按需扩大服务器规模之外,Kimi将另一项中心放在了对现有模型推理的“降本增效”上。
这项技术的费用,通常是因平台或服务提供商维护和提供缓存服务而对客户收取。以网购类比,如果用户经常使用同一个购物网站、App,那么这个网站/App很可能就会在系统中单独创建一个数据集,将用户ID、购物车内容、偏好设置信息存储其中。
而在大模型的使用场景中,如果用户向系统提交了一个请求,比如询问一系列问题,或者给Kimi甩过去一篇万字长文本要求生成报告,大模型在处理请求时就需要理解用户的查询上下文,包括之前的问题、相关话题或者某些领域的特定信息。
这部分推理出的中间结果和计算出的关键信息往往在用户后续的问答中会被反复提及(调用),将他们缓存起来以便后续请求时可以快速访问,是一个相对节省算力资源的选择。
并非是浏览器那种为了方便用户登录而记录用户名和密码,这种缓存首先降低的是模型反复阅读、推理所消耗的资源量,对结果生成效率也会有一定程度提升。利用缓存的上下文信息,大模型可以快速生成响应或推荐内容,而不需要从头开始重新计算。从而对用户提出相关问题或需要相关信息加速响应,减少浪费时间的等待。
这种有助于提高系统的响应速度和处理效率,同时保持对话或文本生成的连贯性和准确性的缓存机制,对于提供流畅的用户体验和优化资源使用来说会相当关键。
尤其在未来可能面对来自B端、更多的用户和更集中的数据处理请求时,快速响应并高效处理的价值可能进一步突出。
One More Thing
to B动作频频的月之暗面,近期还喜提一笔来自鹅厂的大额融资。
市场消息显示,腾讯参与了月之暗面最新一轮3亿美元融资,完成后将使得公司市值升至33亿美元,成为国内大模型初创企业中估值最高的一家。
月之暗面并未对此事做出回应,但据称有接近腾讯方面的消息源表示参投属实。
至此,被誉为“新AI四小龙”的智谱AI、MiniMax、百川智能和月之暗面,四家公司背后的投资阵营都已有了腾讯及阿里巴巴的参与。
BAT中百度更多选择做好自己,AT则继续通过创投多点下注。
初创公司忙于卷技术做应用,而大厂们似乎已经将注意力的一部分,放在了投资回报率,亦或是未来行业格局的话语权上。



 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的