
一提到提高大模型长文本能力,就想到长度外推或者上下文窗口扩展?
不行,这些都太费硬件资源了。
来看一个奇妙新解:
和长度外推等方法使用KV缓存的本质不同,它用模型的参数来存储大量上下文信息。
具体办法就是建一个临时Lora模块,让它仅在长文本生成过程中“流式更新”,也就是用先前生成的内容不断作为输入来充当训练数据,以此保证知识被存进模型参数中。
然后一旦推理完成,就丢掉它,保证不对模型参数产生长久影响。
这个方法可以让我们不用扩展上下文窗口的同时,随便存储上下文信息,想存多少存多少。
实验证明,这种方法:
既可以显著提高模型长文本任务质量,实现困惑度下降29.6%,长文本翻译质量(BLUE得分)提高53.2%;
还能兼容并增强现有大多数长文本生成方法。
最重要的是,能大大降低计算成本。
在保证生成质量小幅提升(困惑度降低3.8%)的同时,推理所需的FLOPs降低70.5%、延迟降低51.5%!
具体情况,我们翻开论文来看。
建个临时Lora模块用完即丢
该方法名叫Temp-Lora,架构图如下:
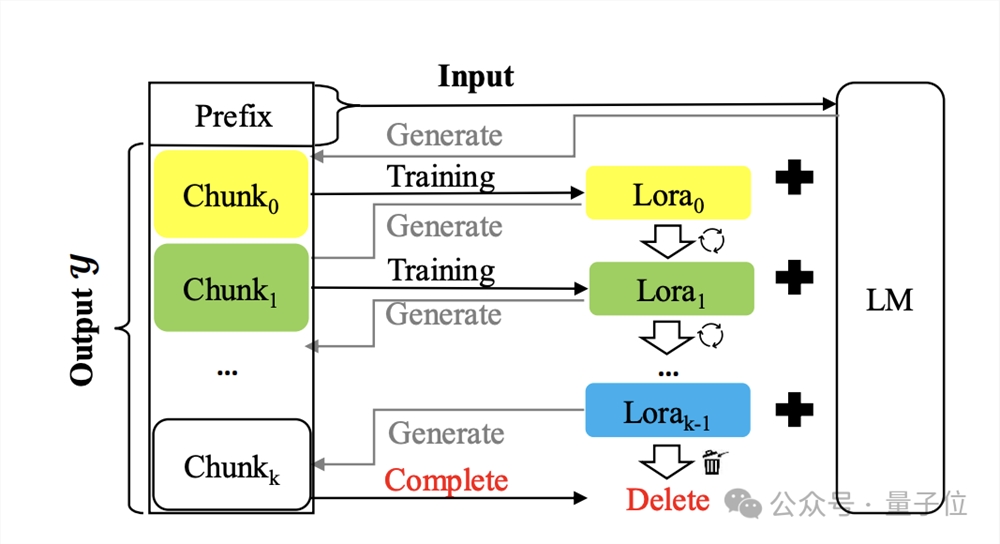
其核心就是以自回归的方式用先前生成的文本上逐步训练临时Lora模块。
该模块适应性很强可以不断调整,因此对不同远近的上下文都能深入理解。
具体算法如下:
在生成过程中,token是逐块生成的。每次生成块时,使用最新的Lxtoken作为输入X生成后续token。
一旦生成的token数量达到预定义的区块大小∆,就使用最新的块启动Temp-Lora模块的训练,然后开始下一个块生成。在实验中,作者将∆+Lx设置为W,以充分利用模型的上下文窗口大小。
对于Temp-Lora模块的训练,如果在没有任何条件的情况下,学习生成新的块可能构不成有效的训练目标,并导致严重的过拟合。
为了解决这个问题,作者将每个块前面的LT标记合并到训练过程中,将它们用作输入,将块用作输出。
最后,作者还提出了一种称为缓存重用(Cache Reuse)策略来实现更高效的推理。
一般来说,在标准框架中更新Temp-Loramo模块后,我们需要使用更新的参数重新计算KV状态。
或者,重用现有的缓存KV状态,同时使用更新的模型进行后续的文本生成。
具体来说,只有当模型生成最大长度(上下文窗口大小W)时,我们才使用最新的Temp-Lora模块重新计算KV状态。
这样的缓存重用方法就可以在不显著影响生成质量的情况下加快生成速度。
关于Temp-Lora方法的介绍就这么多,下面主要看测试。
文本越长,效果越好
作者在Llama2-7B-4K、Llama2-13B-4K、Llama2-7B-32K以及Yi-Chat-6B模型上上对Temp-Lora框架进行了评估,并涵盖生成和翻译这两类长文本任务。
测试数据集一个是长文本语言建模基准PG19的子集,从中随机抽取了40本书。
另一个是来自WMT2023的国风数据集的随机抽样子集,包含20部中文网络小说,由专业人员翻译成英文。
首先来看PG19上的结果。
下表显示了PG19上带有和不带有Temp-Lora模块的各种型号的PPL(困惑度,反映模型对于给定输入的不确定性,越低越好)比较。将每个文档划分为0-100K到500K+token的片段。
可以看到,所有型号经过Temp-Lora之后PPL都显著下降,并且随着片段越来越长,Temp-Lora的影响更加明显(1-100K仅降低3.6%,500K+降低13.2%)。因此,我们可以简单地得出结论:文本越多,使用Temp-Lora的必要性就越强。
此外我们还能发现,将块大小从1024调整到2048和4096导致PPL略有增加。
这倒是不奇怪,毕竟Temp-Lora模块是在之前块的数据上训练的。
这个数据主要是告诉我们块大小的选择是生成质量和计算效率之间的关键权衡(进一步分析可以查阅论文)。
最后,我们还能从中发现,缓存重复使用不会导致任何性能损失。
作者表示:这是一个非常令人鼓舞的消息。
下面是国风数据集上的结果。
可以看到,Temp-Lora对长文本文学翻译任务也有显著影响。
与基础模型相比,所有指标都有显著改进:PPL降低了-29.6%,BLEU得分(机器翻译文本与高质量参考翻译的相似度)提高了+53.2%,COMET得分(也是一个质量指标)提高了+8.4%。最后,是计算效率和质量方面的探索。
作者经实验发现,使用最“经济”的Temp-Lora配置(∆=2K,W=4K),能将PPL降低3.8%的同时,节省70.5%的FLOP和51.5%的延迟。
相反,如果我们完全忽略计算成本,使用最“豪华”的配置(∆=1K和W=24K),也可以实现5.0%的PPL降低,并额外增加17%的FLOP和19.6%的延迟。
使用建议
总结以上结果,作者也给出了实际应用Temp-Lora的三点建议:
1、对于需要最高级别长文本生成的应用,在不更改任何参数的情况下,集成Temp-Lora到现有模型中,就能以相对适中的成本显著提高性能。
2、对于看重最小延迟或内存使用的应用,可以通过减少输入长度和在Temp-Lora中存储的上下文信息来显著降低计算成本。
在这种设置下,我们可以使用固定的短窗口大小(如2K或4K)来处理几乎无限长的文本(在作者的实验中为500K+)。
3、最后,请注意,在不含大量文本的场景中,例如预训练中上下文比模型的窗口大小还小,Temp-Lora就是毫无用处的。
作者来自保密机构
值得一提的是,发明这么简单又创新的办法,作者却没有留下太多出处信息:
机构名称直接落款“保密机构”,三位作者的名字也只有完整的姓。不过从邮箱信息来看,可能来自港城大、港中文等学校。
最最后,对于这个方法,你觉得怎么样?
论文:
https://arxiv.org/abs/2401.11504



 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的