

近日,OpenAI 宣布最新 GPT-4 Turbo with Vision 模型已经通过 OpenAI API 向开发人员开放。
该模型延续了 GPT-4 Turbo 系列 128,000 个 token 的窗口大小,以及截止至 2023 年 12 月的知识库,最大的革新之处在于其新增的视觉理解能力,可处理和分析多媒体输入信息。OpenAI 发言人表示,这些变化有助于简化开发人员的工作流程并打造更高效的应用程序,因为“过去,开发者需要调用不同的模型来处理文本和图像信息,但现在,只需一次 API 调用,该模型就可以分析图像并应用推理。”
开发利器?
现在大家可以通过文本格式 JSON 和函数调用来请求使用该模型的视觉识别和分析功能。函数调用会生成一个 JSON 代码片段,供开发人员在其连接的应用程序中自动执行操作,例如发送电子邮件、发布在线内容、进行购买等。
OpenAI 在其 API 页面上提醒道,在执行会影响现实世界操作之前,强烈建议内置用户确认流程。
OpenAI 开发者团队也分享了一些使用该模型的有趣用例,主打一个非常酷的实时屏幕交互效果。
例如,热门初创公司 Cognition,其“世界首位 AI 软件工程师 Devin”使用的就是 GPT-4 Turbo with Vision ,它利用了该模型的视觉能力来执行各种编码任务。
还有一家名为 Healthify 的健康 & 健身平台,提供健康跟踪和人工智能增强的健康指导,目前拥有超过 4000 万用户。Healthify 利用 GPT-4 Turbo with Vision 来扫描用户膳食的照片,通过照片识别来提供营养见解。
融入实际业务时,GPT-4 Vision 表现得也相当强悍。Healthify 分享了他们的使用感受,表示 GPT-4 T Vision 准确性远超现有水平,识别多种食物;集成简易,完成原型验证后,只需将 OpenAI API 添加到现有管道即可;开箱即用,微调简单,无需大量配置。另外,还能利用 OpenAI 词嵌入模型,成功解决如何匹配食物的难题。Healthify 团队需要将 GPT-4 返回的食物名称与自身系统中的食物名称进行匹配。技术副总裁 Abhijit Khasnis 评论道:“GPT 是一个独立的模型,拥有自己的食物名称字典。Healthify 也有自己的食物名称,我们一直在尝试解决匹配问题。当我们测试 OpenAI 词嵌入模型时,发现相似度匹配准确性极高!”
一些 Twitter 网友也纷纷尝鲜。
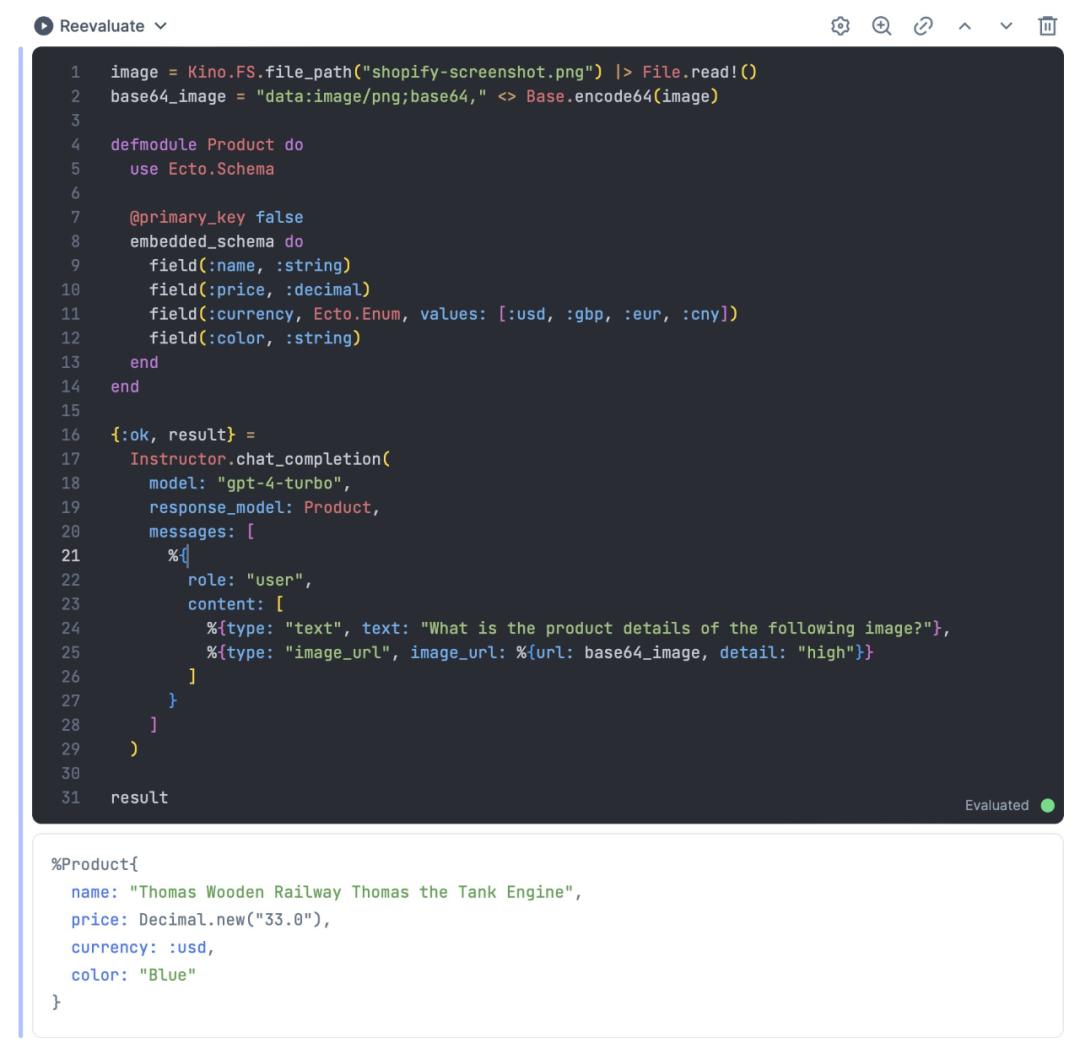
其中一位开发者表示,现在他通过使用 instructor_ex ,无需调用其他库,就能更可靠地从图像中提取数据,“从此告别 mode: :md_json 了”。
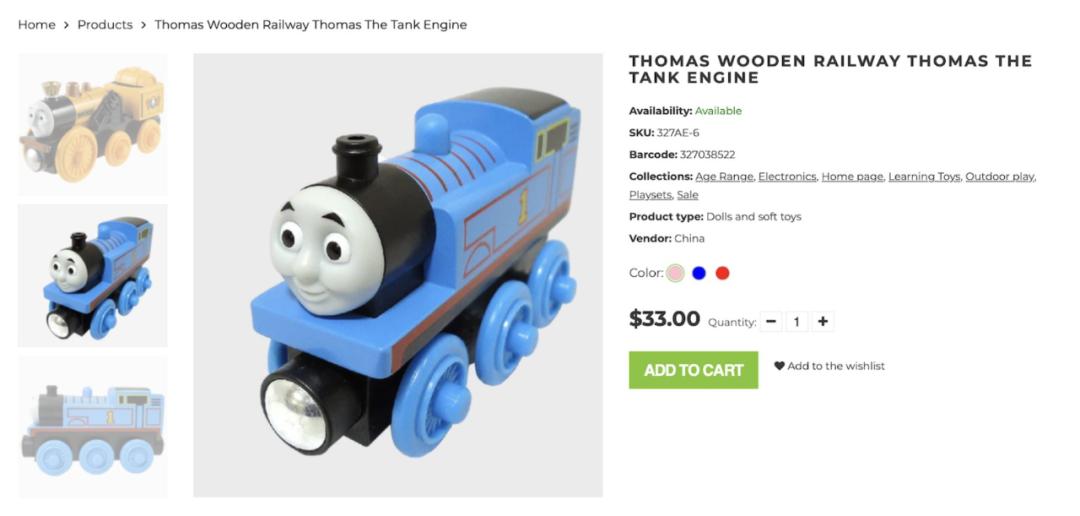
例如,我们可以轻松从这幅卖家图片中,提取到物品名称、价格、颜色信息。
还有一位以构建人工智能应用为生的程序员,尝试了下用 GPT-4 Vision 重新创建一个 Hacker News 的网页,他表示这是“将屏幕截图转换为应用程序的最快方法”。
![]()
还有一位网友,制作了一个图片转测验创作者工具,可以上传来自教科书或报纸的任何截图,并即时生成测验供练习!还能支持多种形式的测验,如:单选题、多选题、填空题、判断题、简答题等。
完成这个功能的开发,他只用了 NextJS 14 + Supabase + GPT-4。看起来,GPT-4 Vision 确实极大地简化了前端开发。
新模型的编程能力是否变强了?
从目前网友的一些测试来看,受 GPT-4 Vision 影响最大的就是前端开发人员了,那么该模型的整体编程能力是否上升了呢?
有些出乎意料的是,有测评表示 GPT-4 Vision 编程能力反而是越来越糟糕了。
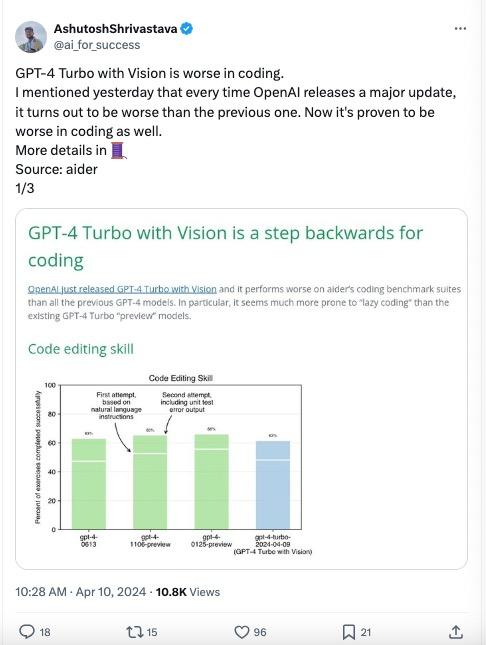
Aider 是一家开发 AI 结对编程工具的公司,他们依靠代码编辑基准对 LLM 进行了定量评估:“在 aider 的代码基准测试套件上,其性能表现低于所有之前版本的 GPT-4 模型。”
该测试是使用 aider 完成 133 个 Exercism Python 编码练习 ( https://github.com/exercism/python)
对于每个练习,LLM 会尝试两次来解决每个问题。在首次尝试中,它将获得初始存根代码和编码任务的英文描述。如果测试全部通过,就表示完成了任务。如果有测试失败,aider 会向 LLM 发送失败的测试输出,并让它进行第二次尝试以完成任务。
GPT-4 Turbo with Vision 在这项基准测试中的得分仅为 62%,是现有 GPT-4 模型中得分最低的。其他模型的得分在 63-66% 之间时,这个最新的模型只是稍有退步,与 gpt-4-0613 相比差距并不明显。
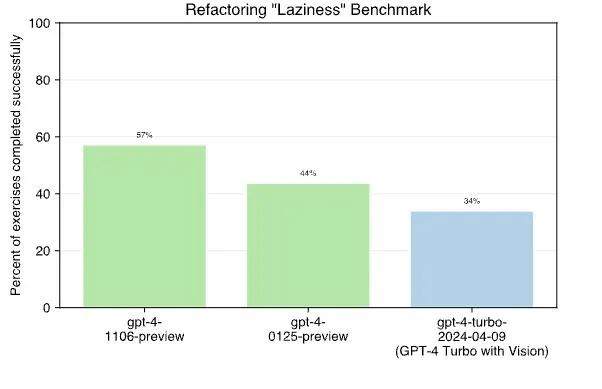
此前 GPT-4 Turbo preview 模型因在编码时“偷懒”,受到了不少业界开发者的批评。它们经常省略所需的代码,而在注释中留下“在此处实现方法”之类的语句。在惰性测试中,GPT-4 Vision 显然是最“懒惰”的那个:只获得了 34% 的分数。

如果编程能力真的“倒退”了,那显然是一个糟糕的结果。
但也有人表示,将编程 / 开发这一严谨的学科贬称为“编码”才是一种更大的倒退。事实上,要开发出架构良好、易于维护且安全的软件,也不仅仅是写代码。
据 Tech Republic 报道,编写实际代码通常只占软件开发人员工作时间的一半以下,甚至在许多情况下,编码时间仅占 20%。这意味着即使像 GPT-4 这样的系统能够完美运行,它们也无法完全替代人类软件开发人员的工作。
另外,技术只是工具,无法替代人类的创造力和沟通能力。开发人员需要与客户会谈、了解他们的需求,并将复杂的问题分解成可解决的组件。这些工作需要丰富的经验和专业知识,并非简单的代码生成工具所能替代。
所以,不管怎么说,就算 GPT-4 Vision 能一键生成网页应用了,那也离替代人类开发者还远。



 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的