
微软发布了其最新的大型语言模型系列,Phi-3,包括Phi-3Vision、Phi-3Small7B和Phi-3Medium14B型号。这些模型在性能上与当前领先的大型模型相媲美,同时在特定领域提供了一些独特的优势。
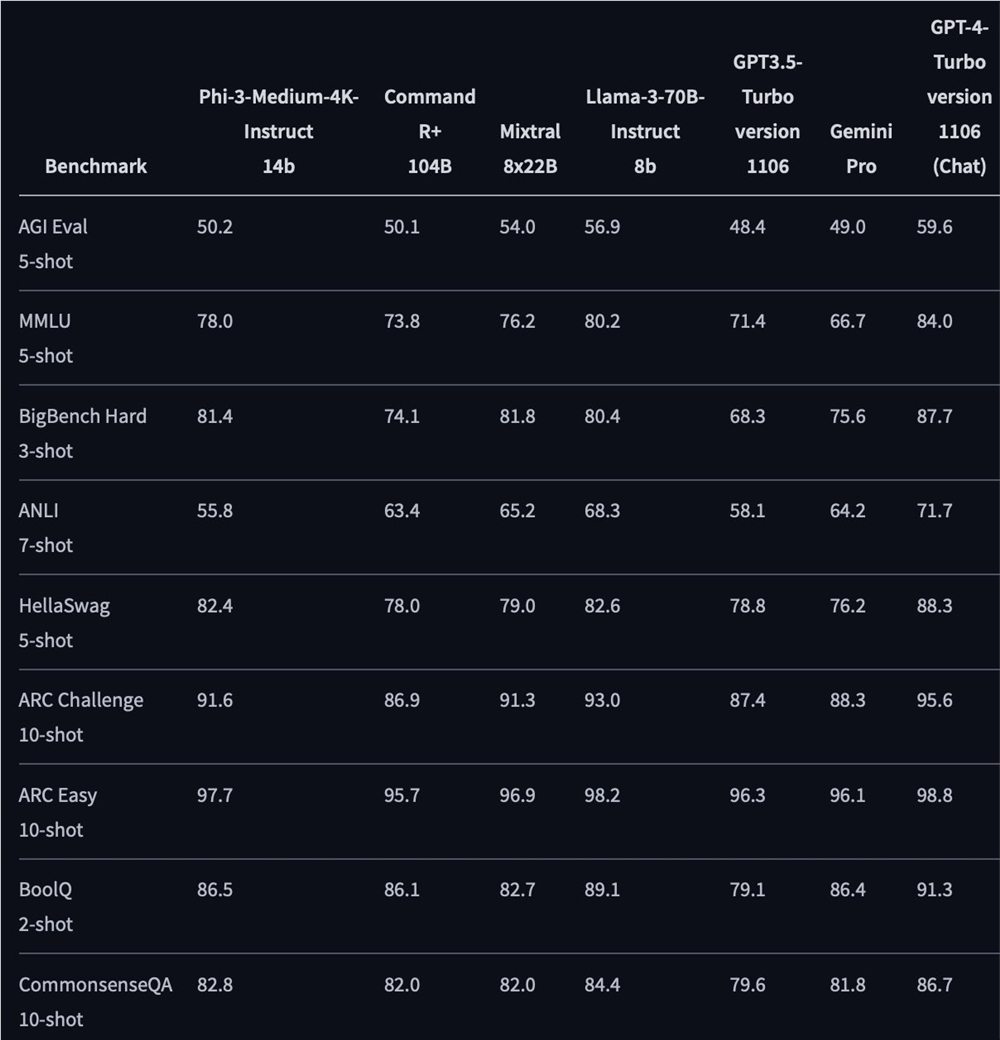
Phi-3Medium14B 型号的性能与Mixtral8x22B和Llama370B相当,甚至超过了Command R+104B和GPT3.5。这表明微软的这个模型在大型模型领域具有较强的竞争力。
Phi-3Small7B 型号虽然规模较小,但其性能依然超过了Mistral7B和Llama38B,这使得它在需要处理大量数据但计算资源有限的场景下具有潜在的应用价值。

Phi-3系列模型支持的上下文长度为4K和128K,这为处理长文本数据提供了灵活性。模型规模方面,Medium版本为14B参数,Small版本为7.5B参数,而Vision版本则为4.2B参数。
在训练数据方面,微软使用了4.8T(万亿)令牌对模型进行训练,训练过程持续了42天,使用了512个H100GPU。训练数据集包含了10%的多语言数据,并且采用了经过严格过滤的数据和合成数据,特别是科学和编程教材,这可能有助于模型在这些领域的特定任务上表现更好。
微软还为Phi-3系列引入了一个新的分词器,拥有10万词汇量,这有助于模型更好地理解和生成语言。此外,Phi-3模型的权重兼容AWQ、INT4、ONNX和transformers,这为开发者提供了在不同平台上部署和运行模型的灵活性。
总体而言,微软的Phi-3系列模型在大型语言模型领域展现了强大的性能和灵活性,为研究人员和开发者提供了新的工具和可能性。随着这些模型的发布,我们可以期待在自然语言处理和相关领域出现新的创新和应用。





 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的