
作为《2022年45家国产AI芯片厂商调研分析报告》的一部分,AspenCore分析师团队汇编整理了10款国产AI芯片和10款国际AI芯片,以展示全球AI芯片的最新技术发展。
Top 10国产AI芯片分别来自如下厂商:寒武纪、地平线、昆仑芯科技、阿里平头哥、燧原科技、瀚博半导体、天数智芯、鲲云科技、黑芝麻智能和芯擎科技。(请在文末投票评选出您最喜欢的国产AI芯片)
Top 10国际AI芯片分别来自如下厂商:NVIDIA、Intel、Google、AWS、Qualcomm、Esperanto、Graphcore、Cerebras、Ambarella和Hailo。
在“AI芯片”报告的调研和汇编过程中,处理器IP领导者安谋科技、国产EDA公司合见工软,以及领先的国产AI芯片设计公司瀚博半导体给予了极大的支持,在此深表感谢!
Top 10国产AI芯片
寒武纪第三代云端AI芯片思元370

思元370基于7nm工艺,集成390亿个晶体管,并采用chiplet(芯粒)技术,其最大算力高达256TOPS(INT8),是思元270算力的2倍。基于最新智能芯片架构MLUarch03,集AI训练和推理一体的思元370实测性能表现优秀:以ResNet-50为例,MLU370-S4加速卡(半高半长)实测性能为同尺寸主流GPU的2倍;MLU370-X4加速卡(全高全长)实测性能与同尺寸主流GPU相当,能效则大幅领先。
思元370在一颗芯片中封装2颗AI计算芯粒(MLU-Die),每个MLU-Die具备独立的AI计算单元、内存、I/O以及MLU-Fabric控制和接口。通过MLU-Fabric保证两个MLU-Die间的高速通讯,而不同MLU-Die组合规格可实现多样化的产品,为用户提供适用不同应用场景的高性价比AI芯片。
地平线整车智能计算平台征程 Journey 5

征程5是地平线第三代车规级AI芯片,采用TSMC 16nm FinFET工艺,遵循 ISO 26262 功能安全认证流程开发,并通过ASIL-B 认证。基于最新的双核BPU贝叶斯架构设计,征程5采用八核 Arm Cortex-A55 CPU集群,可提供高达128TOPS等效算力;CV引擎,双核DSP,双核ISP,强力Codec;支持多路4K及全高清视频输入及处理;双核锁步MCU,功能安全等级达 ASIL-B(D);符合AEC-Q100 Grade 2车规级标准。
该芯片面向高级别自动驾驶及智能座舱应用,其外部接口丰富,可接入超过16路高清视频输入,并支持双通道“即时”图像处理;依托BPU、DSP和CPU资源,不仅适用于先进的图像感知算法加速,还可支持激光雷达、毫米波雷达等多传感器融合;具有PCIe 3.0 高速信号接口,双路千兆实时以太网(TSN) 为多传感同步融合提供硬件级支持(PTP);支持预测规划以及H.265/JPEG实时编解码。
昆仑芯2代

由原百度智能芯片及架构部独立而成的昆仑芯科技推出的第二代云端通用AI芯片采用7nm工艺,基于新一代自研XPU-R架构,其算力为256 TOPS@INT8,128 TFLOPS@ XFP16/FP16,最大功耗为 120W;支持GDDR6高性能显存;高度集成ARM CPU,支持编解码、芯片间互联、安全和虚拟化。
硬件设计上,该芯片是率先采用显存的通用 AI 芯片。软件架构上,昆仑芯2大幅迭代了编译引擎和开发套件,支持 C 和 C++ 编程。此外,昆仑2已与飞腾等多款国产通用处理器、麒麟等多款国产操作系统,以及百度自研的飞桨深度学习框架完成了端到端适配,拥有软硬一体的全栈国产AI能力。该芯片适用云、端、边等多场景,可应用于互联网核心算法、智慧城市、智慧工业等领域,还将赋能高性能计算机集群、生物计算、智能交通、无人驾驶等更广泛空间。
阿里平头哥含光800

平头哥于2019年发布数据中心AI推理芯片含光800,基于12nm工艺, 集成170亿晶体管,性能峰值算力达820 TOPS。在业界标准的ResNet-50测试中,推理性能达到78563 IPS,能效比达500 IPS/W。
含光800采用平头哥自研架构,通过软硬件协同设计实现性能突破。平头哥自主研发的人工智能芯片软件开发包,让含光800芯片在开发深度学习应用时可以获得高吞吐量和低延迟的高性能体验。含光800已成功应用在数据中心、边缘服务器等场景。
燧原“邃思”2.5云端AI推理芯片
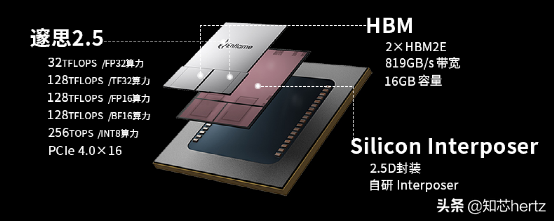
邃思2.5人工智能推理芯片基于第二代GCU-CARA架构,作为云燧i20高性能推理卡的算力核心,具有55mm × 55mm大芯片尺寸,提供从单精度浮点到INT8整型的全精度AI算力;基于HBM2E存储方案,提供819GB/s存储带宽;基于硬件的功耗监测与优化特性,3.5X能效比提升。该芯片可支持视觉、语音、NLP、搜索与推荐等各类应用的模型推理。
新一代“邃思”AI推理芯片采用12nm工艺,通过架构升级,大大提高了单位面积的晶体管效率,可实现与目前业内7nm GPU相匹敌的计算能力。基于12nm成熟工艺带来的成本优势,使得云燧i20加速卡在相同性能表现下性价比更高。
瀚博半导体AI推理芯片SV100
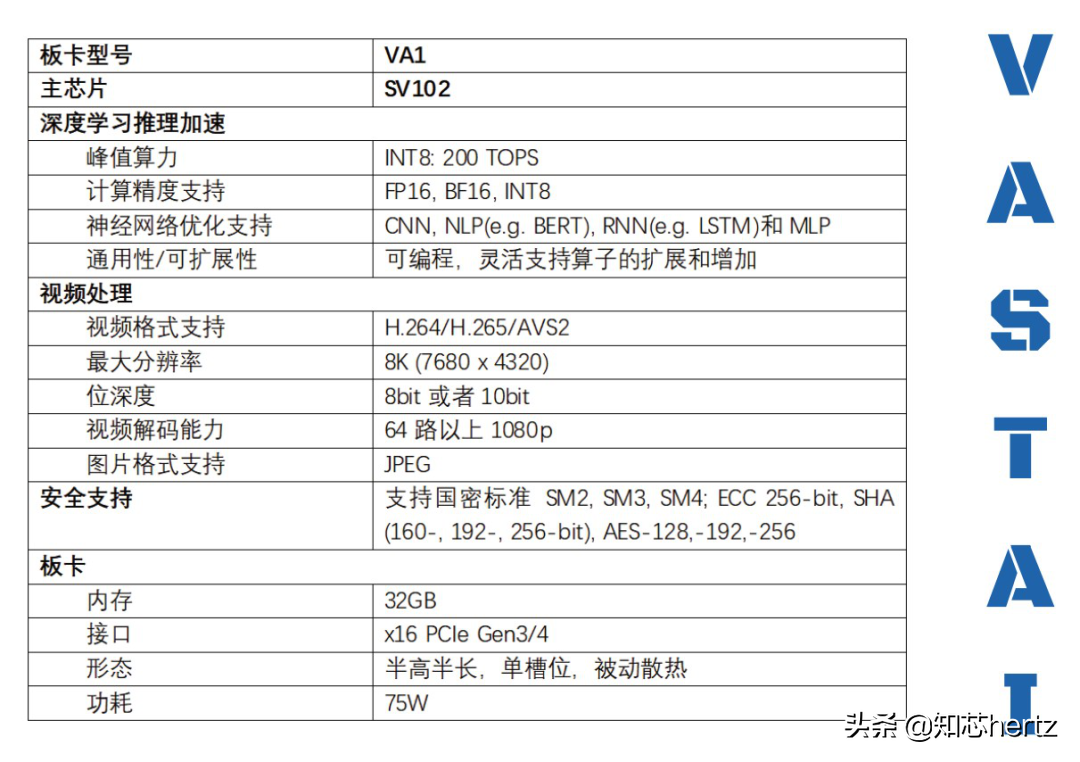
SV100系列芯片(SV102)的定位是面向云端的通用AI推理芯片,其特点主要在高推理性能(单芯片INT8峰值算力200TOPS,也支持FP16/BF16数据类型)、低延时、视频解码性能64+路1080p支持(解码格式支持H.264、H.265、AVS2)。
SV102芯片内部有专门的硬件视频解码单元,其视频处理和深度学习推理性能指标数倍于现有主流数据中心GPU。基于瀚博自研、针对多种深度学习推理负载而优化的通用架构,该芯片可支持计算机视觉、视频处理、自然语言处理和搜索推荐等AI推理应用场景,同时集成高密度视频解码,广泛适用于云端与边缘解决方案,节省设备投资、降低运营成本。
天数智芯GPGPU云端训练芯片

天数智芯基于全自研GPGPU架构的云端训练芯片BI采用台积电7nm工艺,集成了240亿个晶体管,并2.5D CoWoS晶圆封装技术。该芯片可支持FP32、FP16、BF16、INT8等多精度数据混合训练,支持片间互联,其单芯算力可达每秒147T@FP16。
通过丰富的自研指令集,该芯片可支持标量、矢量、张量运算,通过可编程、可配置特性,高效支撑各类高性能计算。这款GPGPU芯片聚焦高性能和通用性、灵活性,为人工智能和相关垂直应用行业提供匹配行业高速发展的计算力,并通过标准化的软硬件生态为应用行业解决产品使用难、开发平台迁移成本大等痛点。
鲲云科技数据流AI芯片CAISA
CAISA芯片采用鲲云自研的定制数据流架构CAISA 3.0,相较于上一代芯片架构在效率和实测性能方面有了大幅提升。CAISA3.0在多引擎支持上提供了4倍的并行度选择,架构的可拓展性大大提高。在AI芯片内,每一个CAISA都可以同时处理AI工作负载,在峰值算力提升6倍的同时保持了高达95.4%的芯片利用率。此外,该芯片在算子支持上更加通用,可支持绝大多数神经网络模型快速实现检测、分类和语义分割部署。
鲲云通过自主研发的数据流技术在芯片实测算力上实现了技术突破,其芯片利用率超过95%,较同类产品提升最高达11.6倍。这种定制化数据流技术不依靠先进的晶圆制造工艺和更大的芯片面积,而是通过数据流动控制计算顺序来提升实测性能,可为用户提供更高的算力性价比。
黑芝麻智能自动驾驶芯片华山二号A1000 Pro

黑芝麻智能 A1000 Pro 采用16nm制程,单芯片INT8算力为106 TOPS,INT4算力为196 TOPS,典型功耗25W,可以满足ISO 26262 ASIL D级别功能安全要求。A1000 Pro 内置高性能 GPU ,可以支持高清 360 度 3D 全景影像渲染,内部可以配置不同数据通路和运算机制,在芯片内部部署互为冗余的双套系统和安全岛校验。
基于单颗、两颗或者四颗 A1000 Pro,黑芝麻的FAD全自动驾驶平台能够满足 L3/L4 级自动驾驶功能的算力需求,支持从泊车、城区道路到高速等自动驾驶场景。
芯擎科技“龍鹰一号”智能座舱芯片

芯擎科技7纳米车规级智能座舱多媒体芯片“龍鹰一号”是由台积电代工生产的7纳米芯片,为智能座舱集成了“一芯多屏多系统”,整合了语音识别、手势控制、液晶仪表、HUD、 DMS 以及 ADAS 融合等功能,可让驾驶人享受更直观、更富个性化的交互体验。
“龍鹰一号”内置8个CPU核心、14核GPU、8 TOPS INT 8可编程卷积神经网络引擎。该芯片达到AEC-Q100 Grade 3级别,采用符合ASIL-D标准的安全岛设计,内置独立的Security Island 信息安全岛,提供高性能加解密引擎,支持SM2、SM3、SM4等国密算法,并支持安全启动、安全调试和安全OTA更新等。强大的CPU、GPU、VPU、ISP、DPU、NPU、DSP异构计算引擎,以及与之匹配的高带宽低延迟LPDDR5内存通道和高速大容量外部存储,为智能座舱应用提供全方位的算力支持。
Top 10国际AI芯片
NVIDIA A100 Tensor Core GPU

NVIDIA A100 Tensor Core GPU基于NVIDIA Ampere 架构,提供40GB和80GB两种配置。作为NVIDIA数据中心平台的引擎,A100的性能比上一代产品提升高达20倍,并可划分为七个GPU实例,以根据变化的需求进行动态调整。A100可针对 AI、数据分析和 HPC 应用场景,在不同规模下实现出色的加速,有效助力高性能弹性数据中心。
针对深度学习训练,A100 的 Tensor Core 借助 Tensor 浮点运算 (TF32) 精度,可提供比上一代 NVIDIA Volta 高 20 倍之多的性能,并且无需更改代码;若使用自动混合精度和 FP16,性能可进一步提升 2 倍。2048 个 A100 GPU 可在一分钟内大规模处理 BERT 之类的训练工作负载。对于具有庞大数据表的超大型模型(例如用于推荐系统的 DLRM),A100 80GB 可为每个节点提供高达 1.3 TB 的统一显存,而且速度比 A100 40GB 快高达 3 倍。
对于深度学习推理,A100能在从 FP32 到 INT4 的整个精度范围内进行加速。多实例 GPU (MIG) 技术允许多个网络同时基于单个 A100 运行,从而优化计算资源的利用率。在 A100 其他推理性能增益的基础之上,仅结构化稀疏支持一项就能带来高达两倍的性能提升。
Intel神经拟态芯片Loihi 2

英特尔发布的第二代神经拟态芯片Loihi 2面积为31mm,最多可封装100万个人工神经元,而上一代产品面积为60mm,支持13.1万个神经元。Loihi 2运行速度比上一代快10倍,资源密度提高了15倍,且能效更高。Loihi 2有128个神经拟态核心,相较于第一代,每个核心都有此前数量8倍的神经元和突触,这些神经元通过1.2亿个突触相互连接。
Loihi 2使用了更先进的制造工艺——英特尔第一个EUV工艺节点Intel 4,现在每个内核只需要原来所需空间的一半。同时,Loihi 2不仅能够通过二维连接网格进行芯片间的通信,还可以在三维尺度上进行通信,从而大大增加了能处理的神经元总数。每个芯片的嵌入式处理器数量从三个增加到六个,每个芯片的神经元数量增加了八倍。
Loihi 2神经拟态芯片利用尖峰神经网络(SNN,Spiking Neural Networks)可以非常有效地解决很多问题,但目前的困难在于,这种非常不同的编程类型需要以同样不同的方式思考算法开发。目前精通它的人大都来自理论神经生物学领域,Loihi 2仅面向研究领域会限制其市场销售范围。英特尔将Loihi 2与Lava开源软件框架结合起来,希望Loihi衍生品最终出现在更广泛的系统中,从充当嵌入式系统中的协处理器到数据中心的大型Loihi集群。
Google TPU 4


Google第四代AI芯片TPU v4速度达到了TPU v3的2.7倍,通过整合4096个TPU v4芯片成一个TPU v4 Pod,可以达到1 exaflop级的算力,相当于1000万台笔记本电脑之和,达到世界第一超算“富岳”的两倍。除了将这些系统用于自己的AI应用(例如搜索建议、语言翻译或语音助手)外,Google还将TPU基础设施以云服务的方式(付费)开放给Google Cloud用户。
第四代TPU提供的矩阵乘法TFLOP是TPU V3两倍以上,显着提高了内存带宽。TPU v4 pod的性能较TPU v3 pod提升了10倍,将主要以无碳能源运行,不仅计算更快,而且更加节能。
AWS Trainium云端推理芯片
AWS自研的第二款定制机器学习芯片AWS Trainium专门针对深度学习训练工作负载进行了优化,包括图像分类、语义搜索、翻译、语音识别、自然语言处理和推荐引擎等,同时支持 TensorFlow、PyTorch 和 MXNet等。与标准AWS GPU实例相比,基于该芯片的EC2 TRN1实例吞吐量提高30%,可让模型推理成本降低45%。
AWS Trainium与AWS Inferentia 有着相同的AWS Neuron SDK,这使得使用 Inferentia 的开发者可以很容易地开始使用Trainium。AWS Trainium将通过 Amazon EC2实例和 AWS 深度学习 AMIs 以及管理服务(包括 Amazon SageMaker、 Amazon ECS、 EKS 和 AWS Batch)提供。
Qualcomm Cloud AI100
高通Cloud AI 100 推理芯片采用7nm工艺,包含16 组 AI 内核,具有400 TOPS 的 INT8 推理吞吐量,以及4 路 @ 64-bit 的 LPDDR4X-4200(2100MHz)的内存控制器,每个控制器管着 4 个 16-bit 通道,总系统带宽达 134 GB/s。
高通为商业化部署提供了三种不同的封装形式,包括成熟的 PCIe 4.0 x8 接口,以及 DM.2 和 DM.2e 接口(25W / 15W TDP),其功耗分别为:DM.2e @ 15W、DM.2 at 25W、PCIe/HHHL @ 75W。
Esperanto ET-SoC-1

Esperanto基于RISC-V的ET-SoC-1芯片集成了1000 个内核,专为数据中心AI推理而设计。该芯片采用台积电 7nm 工艺,内置160M BYTE SRAM,包含240亿个晶体管。
ET-SoC-1的内核包括1088 个ET-Minion和4个ET-Maxion。ET-Minion是一个通用的 64 位有序内核,具有机器学习的专有扩展,包括对每个时钟周期高达256位浮点数的向量和张量运算。ET-Maxion 是该公司专有的高性能 64 位单线程内核,采用四发射乱序执行、分支预测和预取算法。
Graphcore IPU Colossus Mk2 GC200

Graphcore第二代IPU芯片Colossus MK2 GC200 采用台积电的7nm工艺,架构与前代IPU相似,但核心数目增加到1472个(多出20%),其片内SRAM则增加到900MB(多出3倍)。在互联扩展性方面,相比前代增强了16倍。
包含四颗MK2芯片的系统方案IPU-M2000可扩展至1024个IPU-POD,即512个机架,至多64000个MK2芯片集群之后,其16bit FP算力能够达到16 ExaFLOPs。M2000设备内部包含了一颗Gateway网关芯片,提供对DRAM、100Gbps IPU-Fabric Links、连SmartNIC的PCIe接口、1GbE OpenBMC管理接口,以及M.2接口的访问。M2000在神经网络训练的性能表现上,是上一代的7-9倍,推理则也有超过8倍的性能提升。
Cerebras WSE-2
Cerebras设计和制造的有史以来最大的芯片称为晶圆级引擎(Wafer Scale Engine,WSE),第二代芯片WSE-2采用台积电N7工艺,其面积为46225mm2,包含超过1.2万亿个晶体管,内置85万个内核针对深度学习进行了完全的优化。相比英伟达A100 GPU,WSE要大56倍以上,其片上内存高达40GB,内存带宽高达20 PB/秒,网络带宽高达220 PB/秒。
基于WSE-2的AI加速系统CS-2在保持其系统功耗不变(23 kW)的同时,极大增加了内存和结构带宽。CS-2单个系统的计算处理性能相当于几十上百个GPU,可以把完成最复杂的AI工作负载所需的时间从几个月减少到几分钟。
Ambarella CV52S
基于安霸CVflow架构和先进的5nm制程,CV52S单颗SoC拥有超低功耗,同时支持4K编码和强大的AI处理。该芯片采用双核1.6GHz Arm A76,拥有1MB L3缓存;超强ISP具有出色的宽动态、低光照、鱼眼矫正和旋转处理性能;内置隐私遮蔽功能,可以屏蔽部分拍摄场景;新增PCIe和USB 3.2接口可实现更复杂的多芯片安防系统设计;支持安全启动、OTP和Arm TrustZone等坚如磐石的硬件级数字安全技术,确保安防摄像机设备的信息安全;支持多路视频流输入,通过MIPI虚拟通道接口可接入多达14路摄像机;支持LPDDR4x/LPDDR5/LPDDR5x DRAM。
与上一代芯片相比,主打单目安防摄像机的CV52S系列芯片支持4K60fps视频录制,同时AI计算机视觉性能提高4倍,CPU性能提高2倍,内存带宽增加50%以上。神经网络(NN)性能方面的提升,使得边缘设备上也可以执行更多类的人工智能处理,而不需要上传云端。
Hailo边缘AI处理器Hailo-8

以色列AI芯片公司Hailo的边缘AI处理器Hailo-8 性能达到26 tera/秒(TOPS),具有2.8 TOPS/W的高效能。据该公司称,Hailo-8在多项AI语义分割和对象检测基准测试中的表现优于Nvidia的Xavier AGX、英特尔的Myriad-X和谷歌的Edge TPU模块等硬件。
基于Hailo-8的M.2模块是一个专门针对AI应用的加速器模块,可提供高达26TPOS的算力支持,适合边缘计算、机器学习、推理决策等应用场景。M.2 模块具有完整的 PCIe Gen-3.0 4 通道接口,可插入带 M.2 插座的现有边缘设备,以实时和低功耗深度神经网络推断,可对广泛的细分市场进行推断。


 首页
首页
 AI对话
AI对话
 资讯
资讯  我的
我的